웹 기술을 공부할 때면, 용어의 다양한 의미와 비슷한 개념 간의 차이 때문에 혼란스러울 때가 많습니다. 제게는 서버 사이드 렌더링(SSR)과 서버 컴포넌트의 차이를 구분하는 것이 그러했는데요. 잘 정리된 글을 읽고 이해하는가 싶다가도 얼마안가 혼란이 반복됐습니다.
이 글을 쓰게 된 이유도 SSR과 서버 컴포넌트를 이해하기 쉽지않아 글로써 정리하기 위함이 첫 시작이었습니다. 관련 자료를 읽어보던 중 RFC: React Server Components와 New Suspense SSR Architecture in React 18를 읽고나서, React 18이 단순히 서버 기능이 강화된 버전이 아닌, 기존 클라이언트 중심의 구조를 서버 중심의 구조로 변화시키려는 출발점임을 알게 되었습니다. 또한, 새롭게 도입된 기능을 온전히 활용하기 위해선, 개별 기능들이 어떤 문제를 해결하기 위해 고안되었는지를 우선 이해해야할 필요가 있음을 깨달았습니다.
이전까지는 SSR과 서버 컴포넌트의 단어 간 의미 차이에만 집중하여 개념적인 수준의 이해에 그쳤다면, 신규 기능들이 어떠한 문제를 해결하기 위해 설계 되었는지를 이해하고 나니 이제서야 SSR과 서버 컴포넌트의 차이가 보다 명확하게 다가올 수 있었습니다.
React 18에 추가된 서버 기능으로는 스트리밍 기반의 SSR과 서버 컴포넌트가 있습니다. 이 둘은 독립적인 개념 서로 다른 목적을 갖고 개발 되었습니다. 즉 이 둘을 함께 사용할 수도 있고 개별적으로 사용할 수도 있습니다.
먼저, 스트리밍 기반의 SSR이 어떠한 문제를 해결하는지 설명하겠습니다. 기존 방식 SSR의 렌더링, 그러니까 React 18 이전의 React SSR은 다음의 그림과 같은 순서로 수행됩니다. 앞선 단계의 처리가 완료되어야 다음 단계의 처리를 시작할 수 있는 Waterfall 방식입니다. 최종 결과물을 전달받는 사용자 입장에서 구간별 처리 시간이 길어질수록 서비스에 좋지 않은 경험을 할 수 밖에 없는 구조입니다.
이를 다루고 있는 'New Suspense SSR Architecture in React 18'에는 waterfall 방식의 SSR의 한계를 다음의 세 가지로 설명하고 있습니다.
모든 데이터를 받아와야지만 뭐라도 보여줄 수 있다.(You have to fetch everything before you can show anything)
현재의 SSR 방식에서는 HTML을 렌더링할 때 모든 데이터를 미리 서버에서 준비해야 합니다. 컨텐츠 생성에 필요한 데이터가 하나라도 서버에 도달하지 않는다면 HTML 렌더를 시작할 수 없습니다. 이는 매우 비효율적입니다.
모든 컴포넌트의 JS 코드를 브라우저에 불러와야만 hydration을 시작할 수 있다.(you have to load the JavaScript for all components on the client before you can start hydrating any of them)
서버로부터 받아온 HTML에 상호작용을 위해서는 hydration이 필요합니다. 이를 위해선 클라이언트에서 React를 렌더하여 UI 데이터(=Virtual Dom)를 확보해야 합니다. 서버와 클라이언트가 동일한 트리를 갖고 있어야 하기 때문입니다. React 코드를 서버로부터 로드하는데 오랜 시간이 걸린다면, 사용자 입장에서는 컨텐츠를 볼 수 있지만 상호작용할 수 없는 시간이 길어져 사용자 경험을 저하 시킵니다.
모든 hydration이 끝나야만 브라우저와 상호작용이 가능하다. (You have to hydrate everything before you can interact with anything)
hydration은 전체 페이지 단위로 진행됩니다. React는 hydration을 시작하면 전체 트리의 처리가 끝날 때까지 멈추지 않습니다. 그로 인해 사용자가 상호작용을 원하는 영역이 hydration이 완료됐다 하더라도, 상호작용을 위해선 페이지 전체에 대한 hydration이 완료되기를 기다려야합니다.
기존 SSR의 문제를 요약하면 모든 절차가 순차적으로 수행되므로 개별 단계의 딜레이가 마지막 유저에게 도달하기까지 누적되는 문제가 발생한다는 것입니다.
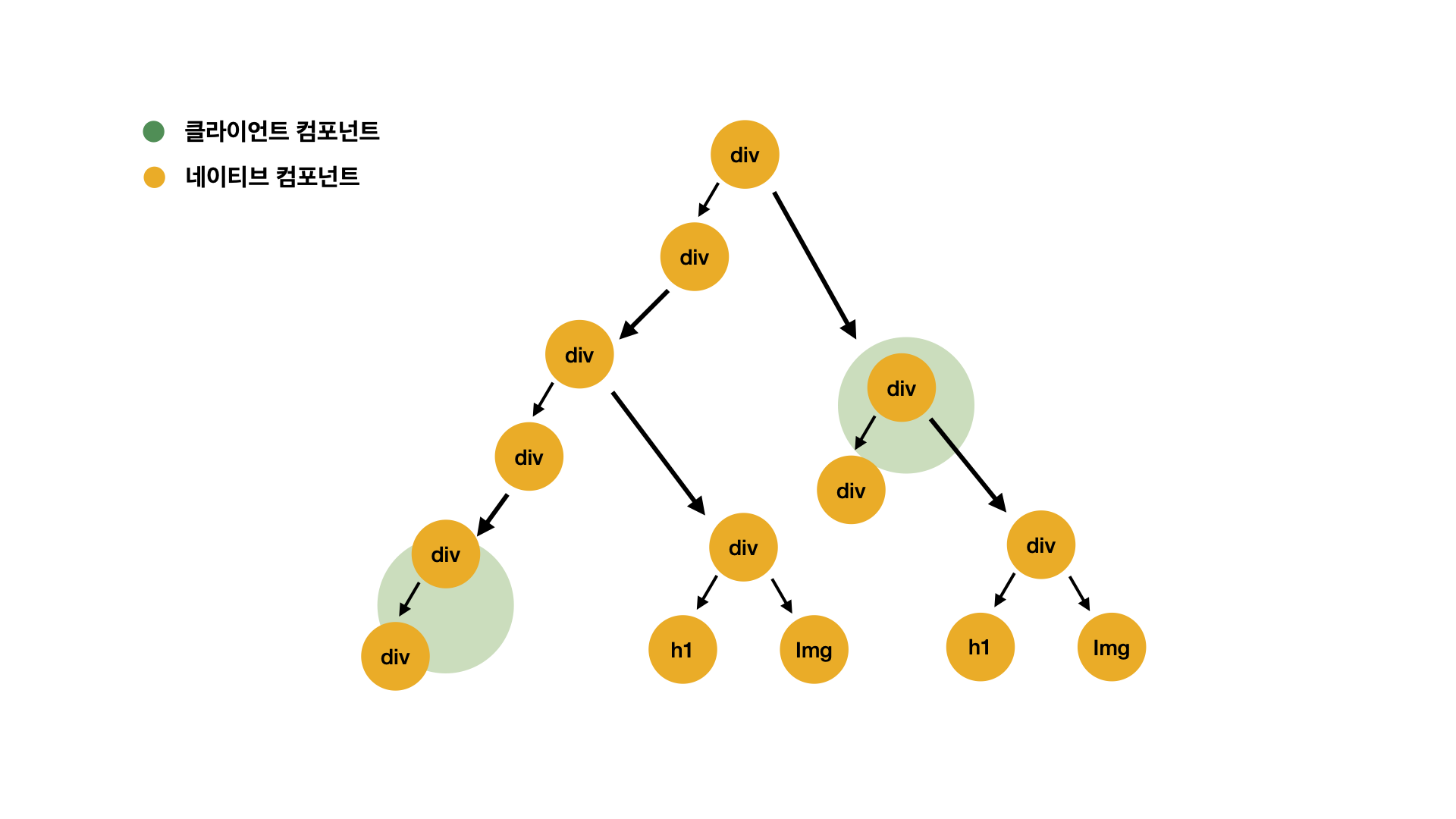
React 18에서는 이러한 waterfall 방식의 렌더링을 해결하기 위해 스트리밍 방식의 렌더링이 도입되었습니다. 이 방식은 아래의 그림과 같이 하나의 페이지를 여러 영역으로 구분하고, 구분된 영역별로 React 렌더가 수행되도록 개선하였습니다.
개별 영역에 필요한 데이터 수집이 완료되면 개별적으로 React를 렌더하여 브라우저에 전송합니다. 페이지 내 개별 영역별로 독립적인 React 렌더가 가능함에 따라, 기존의 waterfall 방식 대비 TTFB와 FCP를 단축할 수 있어 사용자에게는 페이지가 매우 빠르게 로딩되는 경험을 제공할 수 있습니다.
스트림 방식의 SSR은 renderToPipeableStream함수와 Suspense 컴포넌트를 사용하여 구현합니다.
두 기능을 설명하기 앞서 설명에 사용할 예제 코드를 설명하겠습니다. 아래의 코드는 Express 서버를 활용해 React SSR을 구현하는 예제입니다. 사용자가 홈페이지(/)에 접속하면 서버는 renderToPipeableStream 함수를 활용해 React App 컴포넌트를 렌더하고 브라우저 전송합니다. 이떄 renderToPipeableStream은 react-dom/server에서 불러옵니다.
App 컴포넌트 내부 구조로는 html 태그에서 시작하여 Static Content와 Suspense로 감싸진 Dynamic Content로 구성되어 있습니다.
renderToPipeableStream은 두가지 버전이 있습니다. 하나는 SSR을 위한 버전이며 react-dom/server로 불러옵니다. 다른 버전은 서버 컴포넌트를 위해 사용되며 react-server-dom-webpack로 불러옵니다. react-dom과 react-server-dom-webpack는 다른 패키지이므로 함수의 이름이 같을지라도 다른 인자와 내부 구조를 사용하고 있습니다. react-server-dom-webpack의 renderToPipeableStream에 대해서는 서버 컴포넌트에서 다루도록 하겠습니다.
React 내부에서는 SSR에 사용되는 스트림 기능을 Fizz로, 서버 컴포넌트에서 사용되는 스트림 기능을 Flight로 구분짓고 있습니다. 정확히는 파일명에 Fizz 또는 Flight을 기입해 이 둘을 구분합니다.
react-server-dom-webpack 패키지는 React 공식문서에서 다루지 않는 범위이므로 공식문서에 이에 대한 설명이 존재하지 않습니다.
renderToPipeableStream는 인자로 받은 React 컴포넌트를 HTML로 생성하고 이를 브라우저로 스트림합니다. 함수의 결과물로 HTML을 생성하므로 SSR을 위해 사용하는 것을 알 수 있습니다. 함수의 인자로는 reactNode와 options를 받습니다. reactNode는 해당 페이지에 대한 루트 컴포넌트 입니다. 루트 컴포넌트에는 <html> 태그부터 시작하는 전체 문서를 반환해야 합니다.
options에는 예제 코드에서 사용 중인 bootstrapScripts,onShellReady외에도 다양한 설정이 있습니다. 이외 옵션에 대해서는 공식 문서를 참고 바랍니다.
bootstrapScripts
bootstrapScripts은 클라이언트에서 hydrateRoot을 실행시키는 파일명을 설정합니다. 해당 옵션을 사용하면 브라우저로 전달할 HTML 하단에 <script src="/main.js" async=""></script> 을 배치하여 전송합니다.
onShellReady
Shell은 Suspense의 외부 영역을 지칭하는 용어입니다. onShellReady는 초기 Shell이 Render 된 후 실행시키는 콜백 함수입니다. 스트림을 도식화한 그림에서 Shell과 Suspense를 구분할 수 있습니다. 세 개의 진행바 중 가장 상단에 있는 영역이 Shell입니다. shell은 일반적으로 레이아웃이기 때문에 데이터 fetching이 존재하지 않아 바로 렌더되어 브라우저에 제공됩니다.
아래의 html 태그는 홈페이지(/) 접속 요청에 대해 서버가 renderToPipeableStream으로 App 컴포넌트를 렌더한 후 사용자에게 보낸 결과물입니다.
renderToPipeableStream 옵션으로 onShellReady의 shell은 레이아웃 영역에 해당하며, 요청 시 바로 렌더되어 브라우저에 제공된다고 설명했습니다. 아래 HTML이 shell에 해당합니다.
다음으로 App 컴포넌트에는 DynamicContent를 Suspense로 감싸는 형태가 존재했었는데요. 서버로부터 받은 HTML을 보니 보니 App 컴포넌트의 Suspense로 감싸진 내부 영역들이 각각 section 태그와 fallback 컴포넌트로 렌더되어 있음을 확인 할 수 있습니다.
아래의 도식화 그림을 보면, Shell 영역 하단에 서스펜스 1과 2가 존재합니다. 이 둘은 Suspense 내부에 존재하는 DynamicContent 컴포넌트의 Render 흐름을 나타냅니다. 개별 영역은 기존 방식대로 waterfall 방식으로 렌더되고 있지만, Suspense에 의해 독립적인 영역을 보장받으므로 서로의 상태에 방해받지 않고 독립적인 Render 흐름을 유지하고 있습니다.
Suspense 내부의 DynamicContent 렌더에 필요한 데이터가 수집되면, 서버는 해당 영역을 렌더하여 얻은 HTML 조각과 기존의 fallback 함수를 교체하는 스크립트를 서버에 전송합니다.
// 초기 HTML<!DOCTYPE html><html> <head> <meta charSet="utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1" /> <link rel="stylesheet" href="/styles.css"></link> <title>My app</title> </head> <body> <div>Static Contents...</div> <section id="comments-1-spinner"> // <- Spinner로 대체됨 <!-- Spinner --> <img width="400" src="spinner.gif" alt="Loading..." /> </section> <div>Static Contents...</div> ... ... // 데이터 준비가 끝나고 해당 영역의 HTML과 위치를 바꾸는 Script 전송 <div hidden id="comments-1"> <!-- Comments --> <p>First comment</p> <p>Second comment</p> </div> <script> // This implementation is slightly simplified document.getElementById('sections-1-spinner').replaceChildren( document.getElementById('comments-1') ); </script> </body></html><script src="/main.js" async=""></script>
브라우저는 이 HTML 조각을 파싱하여 기존의 spinner를 서버로부터 받은 html 조각을 대체하여 컨텐츠를 로딩합니다. body 태그 내 하단에는 id가 sections-1-spinner인 엘리먼트를 찾아 comments-1인 엘리먼트와 교체하는 script 태그가 존재합니다.comments-1-spinner를 가지고 있는 엘리먼트는 스피너의 부모인 section 태그 입니다. 그리고 comments-1은 서버에서 서스펜스1 영역을 렌더한 html 태그입니다. React는 이와 같은 방식으로 suspense 내부의 동적 영역에 대한 업데이트를 수행합니다.
이로써 New Suspense SSR Architecture in React 18에서 다룬 첫번째 문제인 '모든 데이터를 받아와야만 뭐라도 보여줄 수 있다'를 해결 할 수 있습니다. React 18에 도입된 renderToPipeableStream과 개선된 Suspense 덕분에, 사용자에게 빠르게 화면을 보여줄 수 있고 모든 데이터를 기다릴 필요 없이 suspense에 의해 독립된 영역을 렌더하는 방식으로 화면에 컨텐츠를 제공할 수 있게 되었습니다.
두번째 문제였던 '모든 컴포넌트의 JS 코드를 브라우저에 불러와야만 hydration을 시작할 수 있다.' 또한 Stream과 Suspense를 통해 해결할 수 있게 되었습니다.
React는 번들러를 활용해 React.lazy를 사용한 코드 영역을 다른 코드 영역과 분라히는 기능을 지원합니다. 하지만 React 18이전의 React.lazy는 기존의 SSR 방식과는 궁합이 좋지 않았습니다. React.lazy를 SSR에서 활용하더라도 브라우저에서 모든 JS 코드가 준비되어야만 hydration을 시작할 수 있기 때문입니다. 나중에 로드할 코드를 나누어봤자 의미가 없게 되는 셈입니다.
React 18에서는 서버에서 Suspense를 사용할 수 있도록 업데이트가 되었고 아래의 구조를 통해 React.lazy의 이점을 살릴 수 있게 되었습니다. Suspense 내부 영역은 독립적인 렌더링을 보장받습니다. 그러므로 Suspense 내부 컴포넌트의 JS 코드만 브라우저에 존재하면 부분적인 hydration을 수행할 수 있습니다. 이로서 브라우저에 전체 JS 코드가 로드 될 필요 없게 되었습니다.
마지막으로 '모든 hydration이 끝나야만 해야지만 브라우저와 상호작용이 가능하다.' 문제 또한 Suspense를 통해 해결 할 수 있습니다. React 18 Suspense에서는 사용자의 행동을 감지하여 hydration의 우선 순위를 설정할 수 있습니다.
hydration 되지 않은 영역에 대해 클릭이나 키 입력과 같은 명확한 이벤트(Discrete Events)가 발생하면, React는 해당 Suspense 경계의 코드가 준비된 경우 동기적 hydration을 트리거합니다. 아직 코드를 불러오지 못해 hydration이 불가한 경우, React는 해당 경계의 우선순위를 높여 해당 영역에 대한 코드가 준비되면 먼저 hydration 되도록 설정합니다.
사용자가 특정 영역 위에 마우스를 올리거나 포커스할 경우, 바로 hydration 되진 않지만, 해당 Suspense 영역의 hydration 우선순위가 증가합니다. hydration이 완료되고나면 hydration 되기 전 발생했던 이벤트의 최신 상태가 해당 컴포넌트에 전달됩니다.
이렇게 Selective hydration은 전체 페이지를 한 번에 hydration하는 대신, 사용자의 실제 상호작용이나 잠재적인 상호작용 가능성이 있는 부분을 우선적으로 hydration하여 초기 로드 시간과 응답성을 개선하는 전략입니다. 결과적으로 사용자가 빠르게 반응하는 인터페이스를 경험할 수 있으며, 백그라운드에서는 점진적으로 나머지 영역들이 hydration되어 전체 앱이 완전한 기능을 갖추게 됩니다.
서버 컴포넌트는 앞서 설명한 Waterfall로 처리되는 SSR과는 다른 문제를 해결하기 위해 개발되었습니다. 서버 컴포넌트에 대한 RFC를 설명하는 RFC: React Server Components를 중심으로 서버 컴포넌트가 어떠한 문제를 해결하려는지, 어떠한 방식으로 해결하는지 알아보도록 하겠습니다.
서버 컴포넌트는 React의 Render 단계에서 서버를 활용하자는 아이디어 입니다. 서버 컴포넌트를 이해하기 위해서는 React Render 단계에 대한 이해가 선행되어야 합니다. Render 단계에 대한 보충설명이 필요하다면 [React] 다양한 의미로 쓰이는 렌더링 이해하기 - React 렌더링 사이클를 참고하세요.
서버 컴포넌트(Server Components)는 다양한 React 애플리케이션에서 발생하는 여러 문제를 해결하기 위해 도입되었습니다. 처음에는 여러 문제들을 개별적으로 처리하는 방안을 시도했지만 이러한 시도는 만족스러운 결과를 얻지 못했습니다. React의 근본 문제인 클라이언트 중심적인 구조로 인해 서버를 사용하여 얻는 장점을 충분히 얻을 수 없었습니다.
만약 개발자가 서버를 더 쉽게 활용할 수 있다면, 다음에 설명할 문제들을 모두 해결하면서 작은 앱부터 대규모 앱까지 더 강력한 방식으로 개발할 수 있을 것입니다. 이 문제를 해결함으로써 1. 개발자가 별다른 노력 없이도 좋은 성능을 내기 쉽게 만들 수 있고 2. React에서 데이터를 쉽게 가져올 수 있을 것으로 기대합니다.
React를 사용해본 경험이 있다면, 아마도 다음의 기능이 React에 추가되기를 바랬을 것입니다.
번들 사이즈가 0인 컴포넌트(Zero-Bundle-Size Components)
라이브러리는 개발자 입장에서는 개발을 편리하게 돕지만, 애플리케이션의 코드 크기를 증가시키고 사용자 성능을 저하시킬 수 있습니다. 필요한 기능을 직접 구현하는 것도 가능하지만, 이는 시간이 많이 들고 실수하기 쉽습니다. 또한 라이브러리는 종종 무겁습니다. 트리 셰이킹(tree-shaking) 같은 기법이 도움이 되긴 하지만, 여전히 추가적인 코드가 사용자에게 전송됩니다.
예를 들어, 다음과 같이 마크다운을 렌더링하는 경우 240KB 이상의 JavaScript(압축 시 약 74KB)를 다운로드해야 합니다.
import marked from 'marked'; // 35.9KB (11.2KB gzipped) import sanitizeHtml from 'sanitize-html'; // 206KB (63.3KB gzipped) function NoteWithMarkdown({ text }) { const html = sanitizeHtml(marked(text)); return (/* 렌더링 */); }
위 코드는 개발자 입장에서는 편리하지만, 실제로는 클라이언트에 240KB 이상의 자바스크립트 코드가 전송될 수 있습니다.
그러나 만약 이 컴포넌트를 서버 컴포넌트로 작성하면, 서버에서 정적으로 렌더링한 후 클라이언트에는 필요한 결과만 전달되므로 코드 크기를 줄일 수 있습니다.
// 서버 컴포넌트import marked from "marked"; // 번들 크기 0import sanitizeHtml from "sanitize-html"; // 번들 크기 0function NoteWithMarkdown({ text }) { // 기존 코드와 동일}
완전한 백엔드 접근(Full Access to the Backend)
React에서 서버의 데이터를 가지고 오는 것은 쉬운일이 아닙니다. 보통은 UI를 구성하기 위해 별도의 엔드포인트를 만들거나, 기존 엔드포인트를 사용해야 합니다. 하지만 이런 방식은 초기 설정이나 복잡한 앱 개발 시 번거로움을 초래합니다.
서버 컴포넌트를 사용하면 아래와 같은 방식으로 백엔드 리소스에 쉽게 접근할 수 있어, 클라이언트와 서버 간의 경계를 허물 수 있습니다.
import db from 'db';async function Note({id}) { const note = await db.notes.get(id); return <NoteWithMarkdown note={note} />;}
자동 코드 분할 (Automatic Code Splitting)
코드 분할은 앱을 작은 단위의 번들로 나누어 클라이언트에 전송되는 코드를 줄이는 기법입니다. 전통적으로는 React.lazy와 Dynamic import를 사용해 구현했습니다. 하지만 개발자가 반드시 코드 분할을 신경 써야하며, 동적 import는 클라이언트에서 컴포넌트가 렌더링될 때까지 로딩을 시작하지 않으므로, 코드 로딩이 지연될 수 있는 문제가 있었습니다.
서버 컴포넌트는 이러한 문제를 해결합니다. 클라이언트 컴포넌트에 대한 모든 import가 잠재적인 코드 분할 포인트가 되므로 자동 코드 분할이 이뤄집니다. 어떤 컴포넌트를 사용할지는 서버에서 결정하여, 클라이언트가 더 빨리 필요한 코드를 다운로드할 수 있습니다.
클라이언트에서 데이터를 가져오기 위해 종종 useEffect hook을 사용하여 초기 렌더링 후 데이터를 요청합니다. 이 방식은 부모와 자식 컴포넌트 모두 이런 방식일 경우 순차적으로 데이터를 가져오게 되어 성능 저하를 일으키게 됩니다.
서버 컴포넌트를 사용하면, 데이터 요청을 서버에서 처리하여 클라이언트-서버 간 왕복 호출을 줄일 수 있습니다. 서버에서 데이터 요청을 처리하니, 클라이언트는 별도의 요청을 기다리지 않아도 되어 전체적인 성능이 향상됩니다.
추상화 비용 제거(Avoiding the Abstraction Tax)
React는 자바스크립트를 사용해 강력한 UI 추상화를 가능하게 하지만, 지나친 추상화는 코드 양과 실행 시 오버헤드를 증가시킬 수 있습니다. 정적 타입 언어나 템플릿 언어에서는 컴파일 타임 최적화가 가능하지만, 자바스크립트에서는 쉽지 않습니다.
초기에 React 팀은 Prepack과 같은 AOT(사전 컴파일) 최적화를 시도했지만, 예상대로 동작하지 않는 경우가 많았습니다. 서버 컴포넌트를 사용하면 서버에서 불필요한 추상화를 제거할 수 있습니다. 예를 들어, 여러 레이어의 래퍼(wrapper)가 있더라도 최종적으로 클라이언트에 전달되는 것은 단순한 하나의 요소일 수 있습니다.
통합된 해결책(Unified Solution)
동기에서 언급했듯 이러한 문제는 React가 클라이언트 중심적 구조를 갖기 때문입니다. PHP, Rails와 같은 전통적인 SSR이 이러한 문제를 확실히 해결하는 방법이지만, 이러한 접근법은 풍부한 상호작용을 경험하게 하는데에는 한계가 있습니다.
React 팀이 결국에 깨달은 것은 순수한 SSR도, 순수한 CSR도 충분하지 않는 것이었습니다. 하지만 두 방법을 사용하면 두 개의 언어와 프레임워크, 생태계를 관리하는 등의 번거로움이 발생 것입니다. 또한 서버와 클라이언트 간 데이터 전송, 로직 중복 등의 문제가 발생할 수 있습니다.
서버 컴포넌트는 하나의 언어, 하나의 프레임워크를 사용함에도 SSR과 CSR의 장점에 접근할 수 있게 합니다.
서버 컴포넌트 Render 순서
서버 컴포넌트가 해결하려는 문제를 보듯 서버 컴포넌트는 SSR과는 구분된 개념입니다. 서버를 활용해 React의 단점을 해결하는 방식의 공통점은 있지만 서버 컴포넌트의 경우 SSR과 CSR의 하이브리드 개념으로 이해해야합니다. 하나의 프레임워크를 사용해 SSR과 CSR의 장점을 포함하는 서버 컴포넌트는 앞서 언급했던 기존 React Render의 문제점들을 해결할 수 있었습니다. 반면 SSR에 대한 개선은 페이지의 여러 개별 영역이 독립적인 렌더링이 수행 가능하도록하여 기존 Waterfall 방식의 렌더링의 문제점을 개선할 수 있었습니다.
이제는 서버 컴포넌트를 활용하면 React Render 단계에 어떠한 변화가 발생하는지를 설명하겠습니다. 지금 다루고 있는 내용 또한 RFC: React Server Components에 기반하고 있습니다. 이 RFC에는 흥미로운 내용이 있는데요. RFC에서 이미 프레임워크 사용을 가정하고 있으며, 이를 통해 서버 컴포넌트를 이해할 수 있는 예시로서 사용될 수 있음을 고려하고 있습니다. 개인적인 생각으로는 서버 컴포넌트가 기존의 근간을 흔드는 개념이다 보니 이러한 혼란을 가정하고 점차적으로 안정화하기 위한 목적이지 않나 싶습니다. 이유야 어찌됐건 RFC: React Server Components에서 Render 단계에 프레임워크의 개입을 가정하고 있다는 점을 말씀드리고 싶었습니다.
본격적으로 페이지를 최초 로딩할 때(initial render)와 상태 업데이트를 구분하여 Render 단계를 설명하겠습니다.
초기 로딩(initial render)
[서버, 프레임워크] 요청받은 URL로 부터 추출한 params를 서버 컴포넌트의 Props으로 제공하고, 해당 페이지를 렌더링하도록 React에 요청합니다.
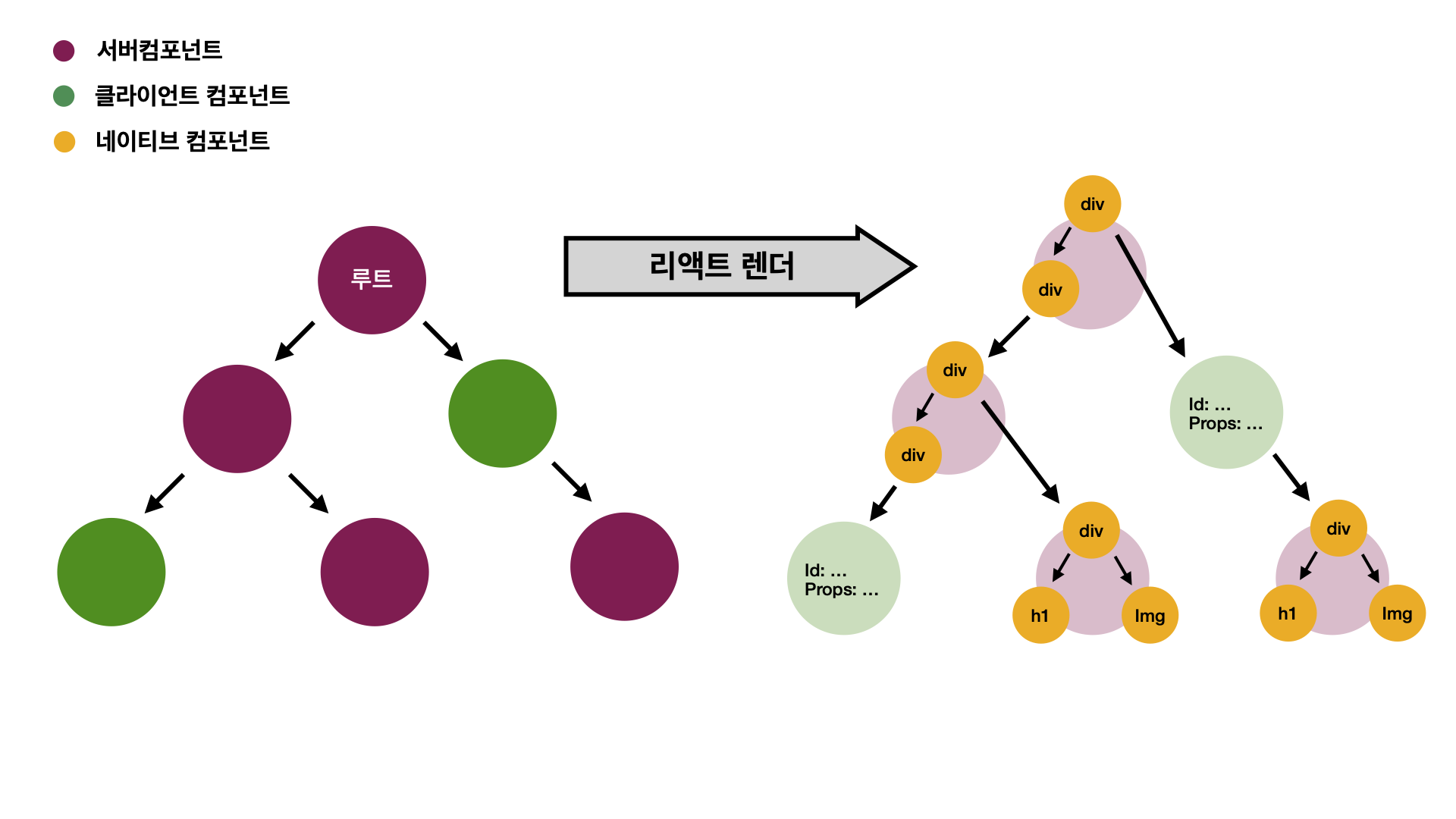
[서버, React] 렌더링은 항상 루트 서버 컴포넌트부터 시작해 하위 트리로 진행됩니다.
하위 트리가 서버 컴포넌트이면 렌더링을 지속합니다. 네이티브 컴포넌트, 클라이언트 컴포넌트, Suspense 컴포넌트를 만나기 전까지 계속해서 하위 트리를 렌더링합니다.
div, span, p와 같은 네이티브 컴포넌트를 만나면 렌더링을 중단합니다. 그리고 네이티브 컴포넌트에 대한 UI 데이터를 JSON serialize합니다.
0:["$","div",null,{"className":"note--empty-state","children":["$","span",null,{"className":"note-text--empty-state","children":"Click a note on the left to view something! 🥺"}]}]
React는 클라이언트 컴포넌트를 만나면 렌더링을 중단합니다. 클라이언트 컴포넌트는 브라우저에서 실행되어야 하므로 실행에 필요한 데이터를 보내야 합니다. 1. 컴포넌트에 포함된 Props를 JSON serialize화 합니다. 2. serialize한 데이터에 컴포넌트 코드를 참조(reference)하는 경로를 포함해 브라우저로 스트림합니다.
0:I{"id":"./src/SearchField.js","chunks":["client2"],"name":"",{"noteId":3,"initialTitle":"I wrote this note today","initialBody":"It was an excellent note."}}
Suspense를 만나면 렌더링을 중단하고 placeholder를 스트리밍합니다. Suspense 영역의 컴포넌트는 데이터를 받아 렌더링을 재개하면, UI 데이터(또는 클라이언트 렌더링에 필요한 데이터)를 스트림합니다. placeholder는 서버로부터 받은 결과값과 교체됩니다.
0:"$Sreact.suspense"
[서버, 프레임워크] 프레임워크는 스트리밍된 응답 데이터를 클라이언트에 점진적(incrementally)으로 반환합니다. 브라우저로 보내는 데이터는 HTML이 아닌 Binary JSON 입니다.
프레임워크에 따라 Server Component와 서버 사이드 렌더링(SSR)을 결합하여 초기 렌더링 결과를 HTML에 첨부해 스트리밍할 수도 있습니다.(Next.js AppRouter에 해당)
서버가 브라우저로 보내는 데이터는 HTML 조각이 아니라 렌더링된 UI 데이터(흔히 Virtual Dom이라고 표현하는 대상)입니다. HTML 대신 UI 데이터를 서버에서 받는 이유는 브라우저에서 실행되는 클라이언트 컴포넌트와 쉽게 병합(reconciliation)하기 위함입니다.
[브라우저, React] React는 받은 응답 데이터를 역직렬화(deserialize)하여 네이티브 요소(HTML 태그)와 클라이언트들을 렌더링합니다.
이 과정은 이루어지며, 전체 스트림이 완료될 때까지 기다리지 않아도 부분적으로 화면에 표시할 수 있습니다.
또한, Suspense를 사용하여 Client Component의 코드가 로딩 중이거나 Server Component가 추가 데이터를 받아오는 동안 개발자가 의도한 로딩 상태(UI)를 표시할 수 있습니다.
모든 클라이언트 컴포넌트와 서버 컴포넌트가 로드되어 React Dom 트리를 완성하면 브라우저 Dom 트리를 생성하여 최종적으로 UI가 사용자에게 보여집니다.
상태 업데이트
클라이언트로부터 업데이트 요청이 들어오면 서버는 초기 로딩과 동일하게 루트 서버 컴포넌트 전체를 렌더합니다. 상태 업데이트에서 기억할 점은 서버 컴포넌트는 변화가 발생한 컴포넌트부터 업데이트하지 않고 전체 서브 트리에 대해 렌더를 수행하는 것입니다.
[브라우저] 해당 URL에 대한 상태 업데이트가 발생합니다.
[서버, 프레임워크] 초기 로딩과 마찬가지로, 요청받은 URL로부터 추출한 params를 서버 컴포넌트의 Props으로 제공하고,React에 해당 페이지를 렌더링 하도록 요청합니다.
[서버, React] 초기 로딩과 동일합니다. 서버 컴포넌트의 하위 트리로 렌더를 수행하고 네이티브 컴포넌트, 클라이언트 컴포넌트, Suspense 컴포넌트 등을 만나면 각자의 방식으로 처리 된 뒤 브라우저에 스트림으로 제공합니다.
[브라우저, React] 서버로부터 받은 UI 데이터와 기존 스크린의 UI 데이터를 비교하여 변화된 컴포넌트를 확인합니다.
서버로부터 받은 렌더링 결과가 HTML이 아니라 UI 데이터(=virtual DOM)이므로, JS 객체인 UI 데이터의 값을 업데이트 합니다.
기존의 데이터에 변경된 부분만 업데이트 하므로 포커스, 입력 중인 텍스트, 혹은 기존 콘텐츠에 대한 UI 상태가 그대로 유지되거나 자연스럽게 전환됩니다.
서버 컴포넌트 예제
React 팀은 서버 컴포넌트의 동작 방식을 설명하기 위해 예제 코드를 제공하고 있습니다. [Github] Server-Component-Demo가 그러한 내용인데요. 내부 코드를 보면서 서버 컴포넌트가 어떠한 흐름으로 React Render 단계에 참여하는지 이해하도록 하겠습니다.
[Github] Server-Component-Demo는 CSR 방식으로 동작합니다.
폴더 구조
server // 서버 역할 수행src--framework // 프레임워크 역할 수행----bootstrap.js----router.js--App.js // 메인 컴포넌트...js files // 기타 컴포넌트
예제 코드의 폴더 구조는 서버 역할을 수행하는 server 폴더, 프레임워크 역할을 수행하는 src/framework 폴더 , App.js를 포함해 기타 컴포넌트가 포함된 src가 존재합니다. 서버 컴포넌트는 기본적으로 프레임워크와 함께 사용하는 것을 가정하기 때문에 src/framework의 코드가 실제 프레임워크 역할을 대신합니다.
사용자가 메인 페이지(/)의 문서를 요청하면 서버는 React를 실행시키는 build/index.html를 브라우저에게 제공합니다.
// server/api.server.jsapp.get( "/", handleErrors(async function (_req, res) { await waitForWebpack(); const html = readFileSync( path.resolve(__dirname, "../build/index.html"), "utf8" ); // Note: this is sending an empty HTML shell, like a client-side-only app. // However, the intended solution (which isn't built out yet) is to read // from the Server endpoint and turn its response into an HTML stream. res.send(html); }));
브라우저는 서버로부터 아래의 HTML을 전송받습니다. head 태그 내부에 main.js 스크립트가 존재합니다. main.js를 구동하면 React 렌더가 시작됩니다.
main.js는 webpack에 의해 번들된 결과입니다. 클라이언트에 필요한 모든 코드들이 하나의 파일안에 들어있다고 생각하시면 쉽습니다. 이 파일은 script/build.js에 의해 생성됩니다. 프로젝트 시작 시 다음과 같이 설정되어 커맨드에 npm start를 입력하면 build.js를 실행하여 번들링을 시작합니다.
"start": "concurrently \"npm run server:dev\" \"npm run bundler:dev\"",..."bundler:dev": "cross-env NODE_ENV=development nodemon -- scripts/build.js",
React를 실행하는 root.render 코드는 ./src/framework/bootstrap.js에 위치합니다. bootstrap 파일 내부를 보면 일반적인 React의 실행코드와 동일해 보입니다. createRoot으로 root 인스턴스를 생성하고 render 메서드로 Root 컴포넌트를 실행해 컨텐츠를 생성합니다.
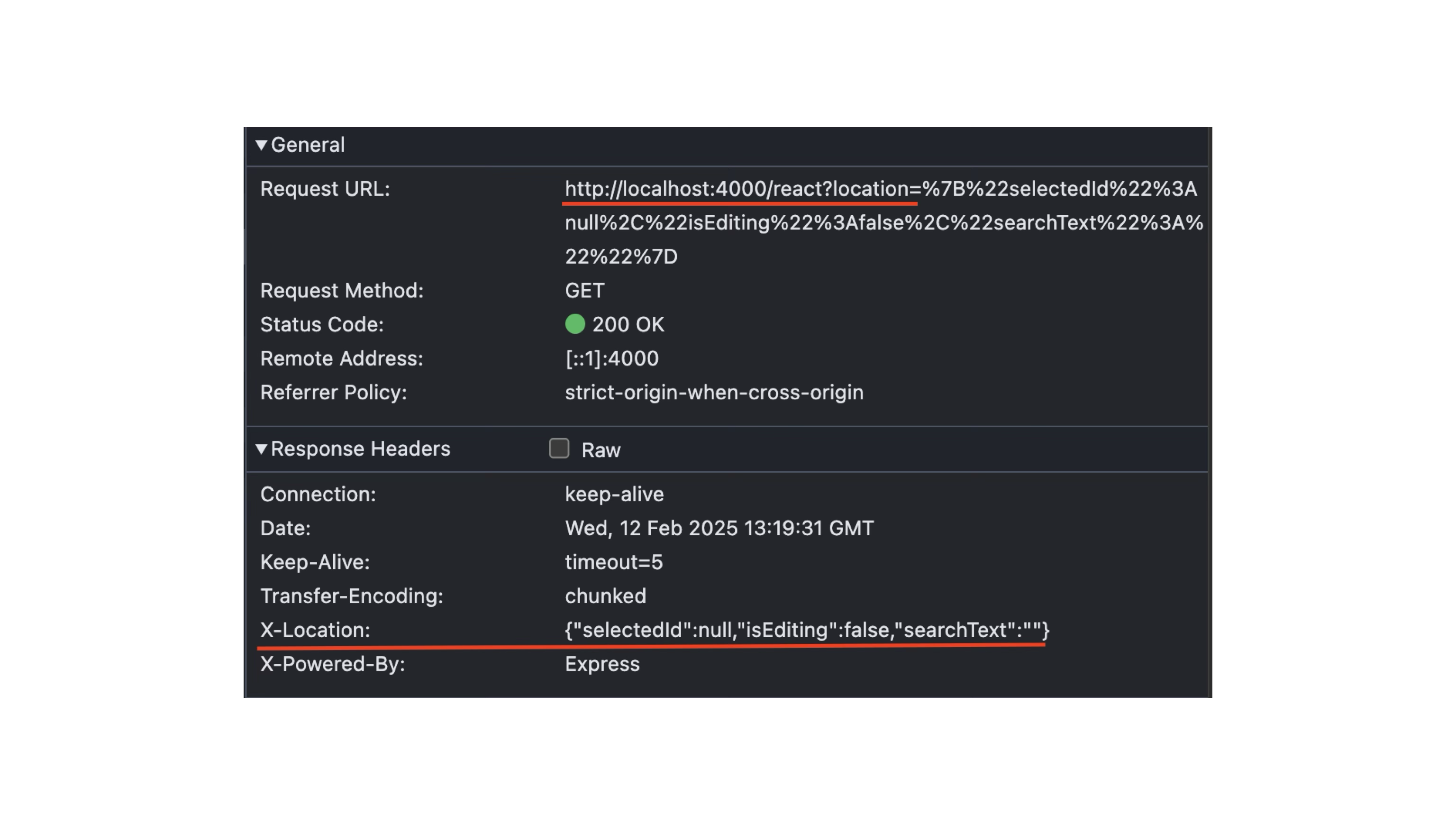
Router 컴포넌트에는 최초 로딩 시 페이지 컨텐츠를 서버에 요청하는 로직이 존재합니다. createFromFetch(fetch('/react?location=' + encodeURIComponent(locationKey)));이 그러합니다. fetch로 서버에 무언가를 요청하고 createFromFetch로 추가적인 작업을 처리하여 컨텐츠를 만듭니다. 컴포넌트 하단을 보니 content 함수는 use 함수를 통해 서버로부터 요청 받은 결과를 리턴하는 것으로 보입니다.
브라우저가 /react 경로로 무언가를 요청하고 있으니 서버의 /react 내부 로직을 보며 어떤 결과를 전달받는지를 알아보겠습니다.
fetch('/react?location=' + encodeURIComponent(locationKey))에 대해 서버는 다음과 같은 순서로 처리합니다. /react에 대한 요청이 들어오면 sendResponse 함수를 실행합니다. sendResponse 함수는 searchParams인 location을 X-location 헤더로 추가한 뒤 renderReactTree를 실행합니다. reactRenderTree 함수는 renderToPipeableStream에서 서버 컴포넌트인 App.js를 렌더하여 결과를 점진적으로 브라우저에 스트림하여 제공합니다.
이때 사용되는 renderToPipeableStream는 react-server-dom-webpack에서 불러오고 있습니다. 앞서 SSR을 설명하면서 언급한 renderToPipeableStream 함수와 달리 webpackMap이라는 인자를 추가로 받고 있습니다.
서버 컴포넌트 버전은 SSR 버전과 다르게 webpackMap 변수를 받고 있습니다. 우의 코드에서는 ../build/react-client-manifest.json의 데이터를 입력으로 사용하고 있음을 확인할 수 있습니다. react-client-manifest.json은 build.js의 결과물이자 브라우저에서 사용되는 함수와 컴포넌트를 json으로 가지고 있습니다. 클라이언트 컴포넌트는 브라우저에서 렌더되어야 하므로 관련 파일 위치, 브라우저로 보내는 파일명(chunk) 등이 포함되어있습니다.
서버는 renderToPipeableStream의 결과를 브라우저에게 제공합니다. 응답을보니 서버에서 처리한 대로 헤더 X-Location에 브라우저의 locationKey가 존재합니다.
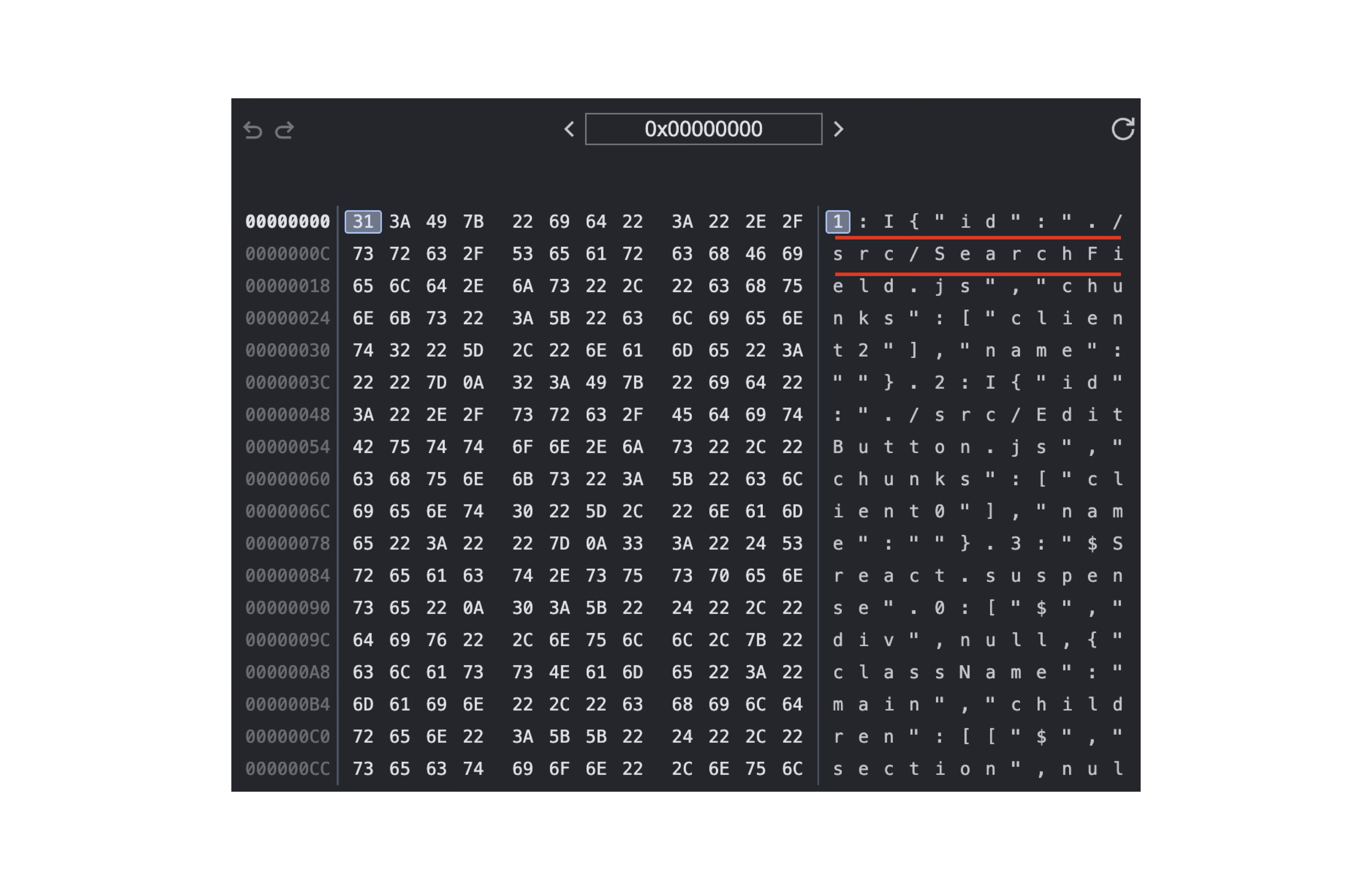
서버가 브라우저에게 보낸 데이터는 바이너리 JSON 입니다. 네트워크 탭 Response를 보면 아래의 응답을 확인할 수 있습니다. 결과 우측에는 바이너리 코드가 어떻게 디코드 되는지 확인 할 수 있습니다. I{"id":"./src/SearchField.js"... 이 보입니다.
이렇게 서버로부터 받은 바이너리 JSON은 createFromFetch함수를 거쳐 React 엘리먼트로 변환됩니다. createFromFetch는 내부적으로 startReadingFromStream를 실행합니다. startReadingFromStream는 내부적으로 processBinaryChunk를 실행하고 processBinaryChunk는 바이너리 JSON을 문자열로 변환 한 후 Deserialize하여 JS 객체 구조인 React 엘리먼트를 생성합니다.
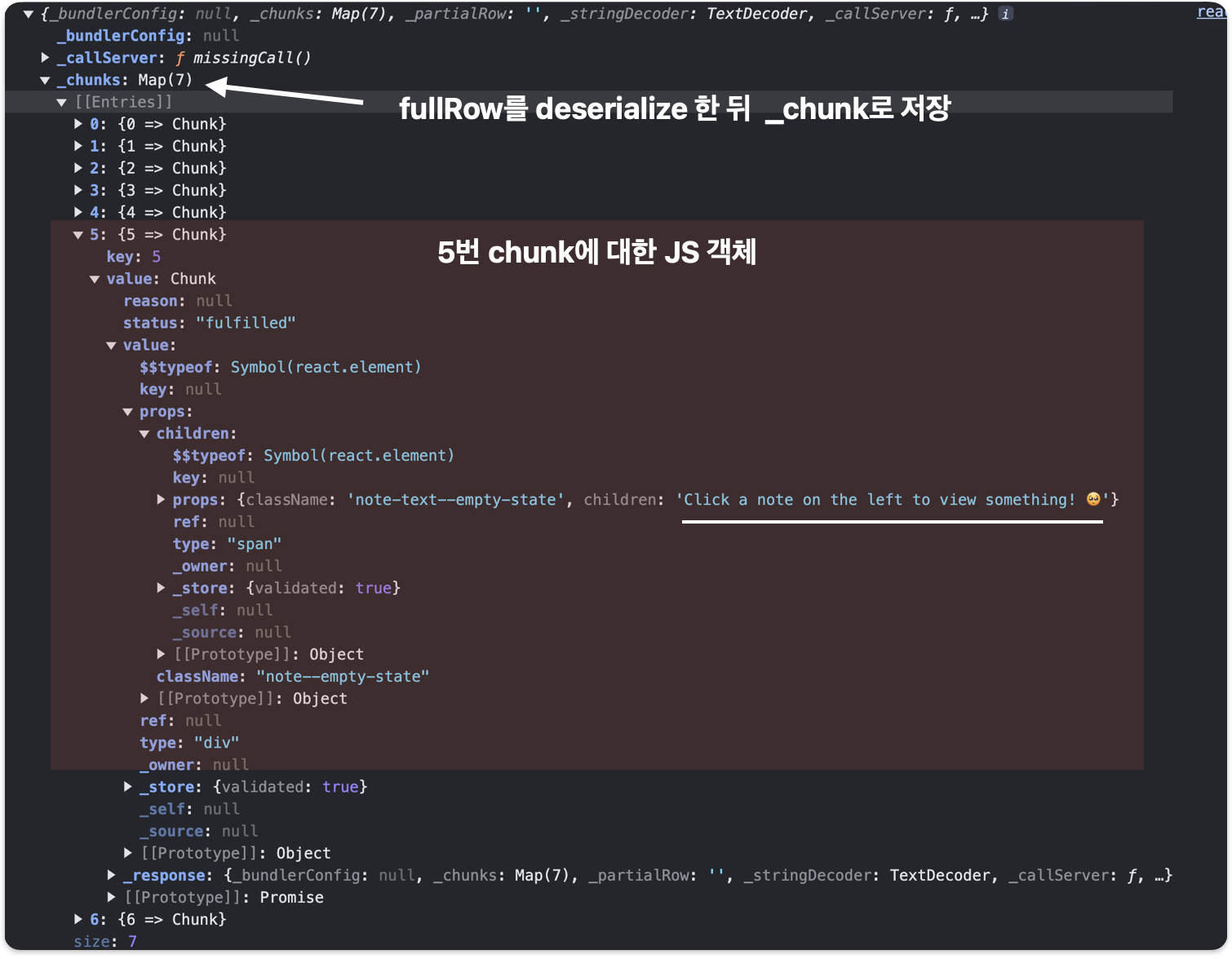
서버로부터 받은 UI 데이터를 직접 확인하고 싶다면 react-server-dom-webpack-client.browser.development.js 파일의 processBinaryChunk 함수 내부에 있는 fullrow와 response 변수를 console.log로 출력하시면 됩니다.
// createFromFetch 코드 경로 :// ./node_modules/react-server-dom-webpack/cjs/react-server-dom-webpack-client.browser.development.jsfunction createFromFetch(promiseForResponse, options) { var response = createResponseFromOptions(options); promiseForResponse.then( function (r) { startReadingFromStream(response, r.body); }, function (e) { reportGlobalError(response, e); } ); return getRoot(response);}// 서버로부터 받은 binary response를 string chunk로 변환하여 buffer에 저장function startReadingFromStream(response, stream) { var reader = stream.getReader(); function progress(_ref) { var done = _ref.done, value = _ref.value; if (done) { close(response); return; } var buffer = value; processBinaryChunk(response, buffer); return reader.read().then(progress).catch(error); } function error(e) { reportGlobalError(response, e); } reader.read().then(progress).catch(error);}function processBinaryChunk(response, chunk) { var stringDecoder = response._stringDecoder; var linebreak = chunk.indexOf(10); // newline while (linebreak > -1) { var fullrow = response._partialRow + readFinalStringChunk(stringDecoder, chunk.subarray(0, linebreak)); //******************* console.log(fullrow); //******************* processFullRow(response, fullrow); //******************* console.log(response); //******************* response._partialRow = ""; chunk = chunk.subarray(linebreak + 1); linebreak = chunk.indexOf(10); // newline } response._partialRow += readPartialStringChunk(stringDecoder, chunk);}
processBinaryChunk 내부의 fullrow는 서버의 바이너리 JSON을 string으로 변환한 결과입니다. console.log로 찍어보니 Response 결과에서 어렴풋이 봤던 내용이 1번째에서 보입니다. 여러 UI 데이터 중에서 5번째 UI 데이터에 🥺 이모티콘이 포함되어 있으니 5번째 UI 데이터를 추적해 보겠습니다.
1:I{"id":"./src/SearchField.js","chunks":["client2"],"name":""}2: .......5:["$","div",null,{"className":"note--empty-state","children": ["$","span",null,{ "className":"note-text--empty-state", "children":"Click a note on the left to view something! 🥺"} <---- ]}]
다음으로 processFullRow로 fullRow를 처리하면 다음 그림과 같이 JS 객체를 얻습니다. _chunk에는 개별 UI 데이터가 저장되어 있음을 볼 수 있습니다.
다시 router.js의 Router함수로 돌아가서, use를 통해 서버로부터 UI 데이터를 실제로 받아옵니다.
content는 서버로에서 렌더한 루트 컴포넌트 입니다. 루트 컴포넌트 내부에는 네이티브 컴포넌트와 클라이언트 컴포넌트 그리고 서스펜스 컴포넌트 세 종류가 존재합니다.
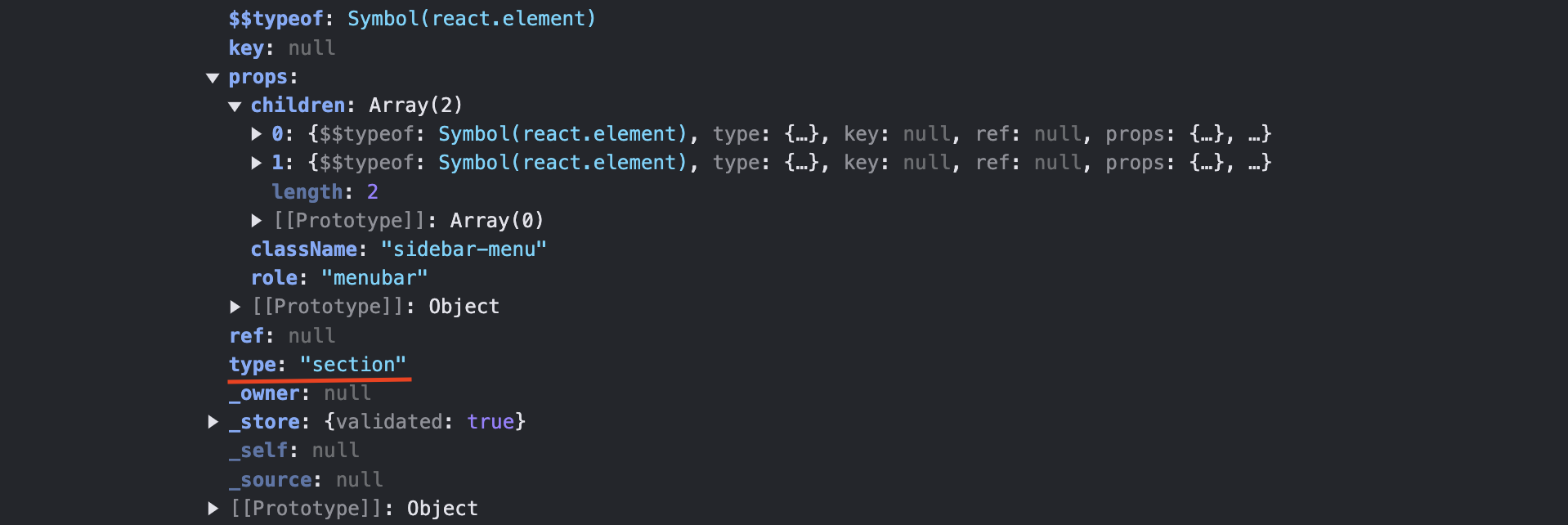
네이티브 컴포넌트
div, section, span 등 html 태그를 포함하는 컴포넌트를 네이티브 컴포넌트라 합니다. 아래의 네이티브 컴포넌트는 section 입니다. 네이티브 컴포넌트는 서버 컴포넌트에서 처리한 연산 결과를 props로 갖고 있습니다. 그러므로 네이티브 컴포넌트에 대한 추가적인 연산을 필요로 하지 않습니다.
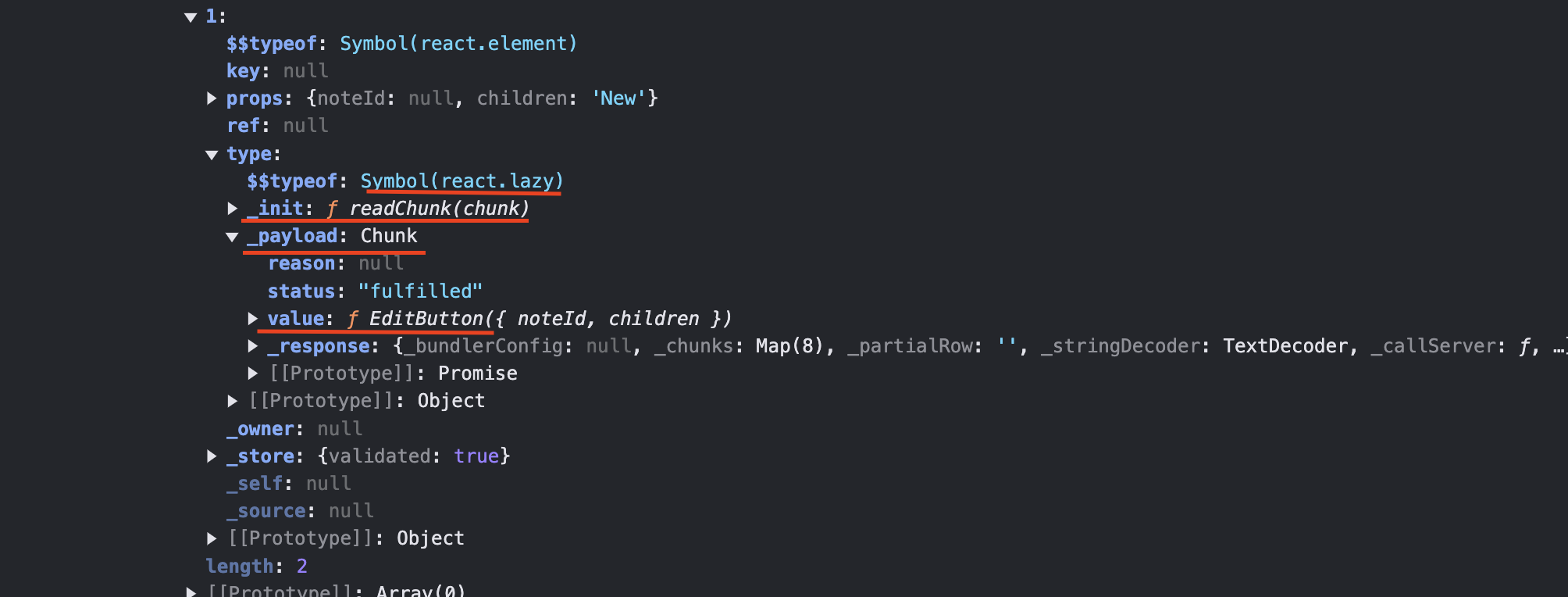
클라이언트 컴포넌트
클라이언트 컴포넌트는 브라우저에서 처리되어야 하는 컴포넌트입니다. 클라이언트 컴포넌트는 Lazy 컴포넌트 타입으로 분류되어 있습니다.
클라우드 컴포넌트가 브라우저에서 실행되기 위해선 다음의 절차를 거칩니다. React 내부에서는 lazy 함수를 다음과 같이 처리합니다.
컴포넌트 내부의 init 함수에 컴포넌트 내부의 payload를 인자로 넣어 실행합니다. 위 그림에서 함수의 _init은 readChunk이며 _payload는 chunk 타입의 객체입니다.
var payload = lazyComponent._payload;var init = lazyComponent._init;init(payload);
readChunk 함수 내부는 initializeModelChunk를 실행합니다. initializeModelChunk는 _payload의 문자열 타입인 value를 parsing 하여 함수로 변환합니다. (위 그림에서의 value는 이미 변환된 결과이므로 f로 표기되고 있습니다.) 클라이언트 React는 함수로 변환된 value를 활용해 렌더를 수행합니다.
323 function readChunk(){} 328 initializeModelChunk() 572 function initializeModelChunk(chunk){ 577 const resolvedModel = chunk.value; 592 const value: T = parseModel(chunk._response, resolvedModel); 3389 function parseModel<T>(response: Response, json: UninitializedModel): T { return JSON.parse(json, response._fromJSON); } 614 const initializedChunk: InitializedChunk<T> = chunk; 615 initializedChunk.status = INITIALIZED; 616 initializedChunk.value = value; }
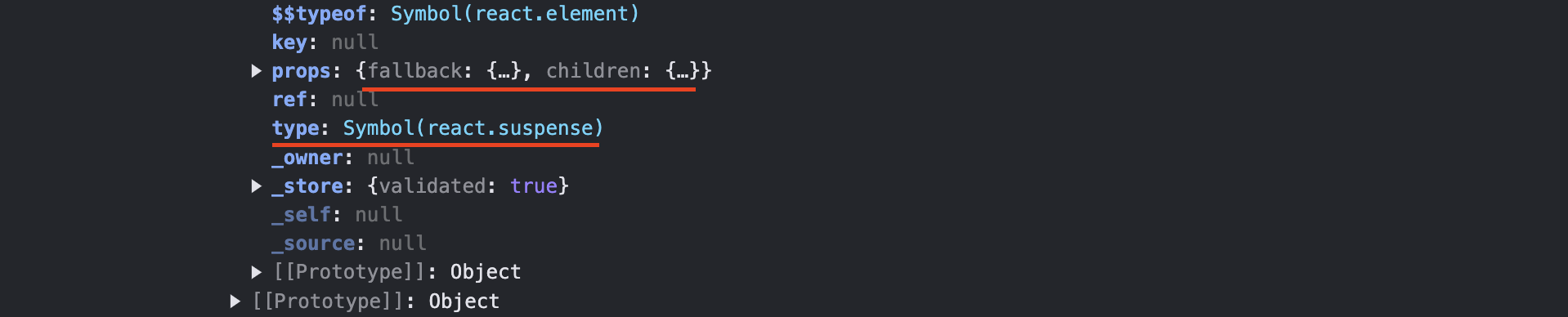
서스펜스 컴포넌트
서스펜스 컴포넌트는 suspense 타입을 갖고 있습니다. props로는 fallback과 children을 가지고 있습니다. children 컴포넌트 내부를 보면 클라이언트 컴포넌트와 마찬가지로 Lazy 컴포넌트 타입으로 분류되어 있습니다.
브라우저 React가 서버로부터 UI 데이터를 받아와 그린 화면입니다. 5번째 UI 데이터에 있는 🥺 이모티콘이 보입니다. 이로서 초기 로딩이 완료됩니다.
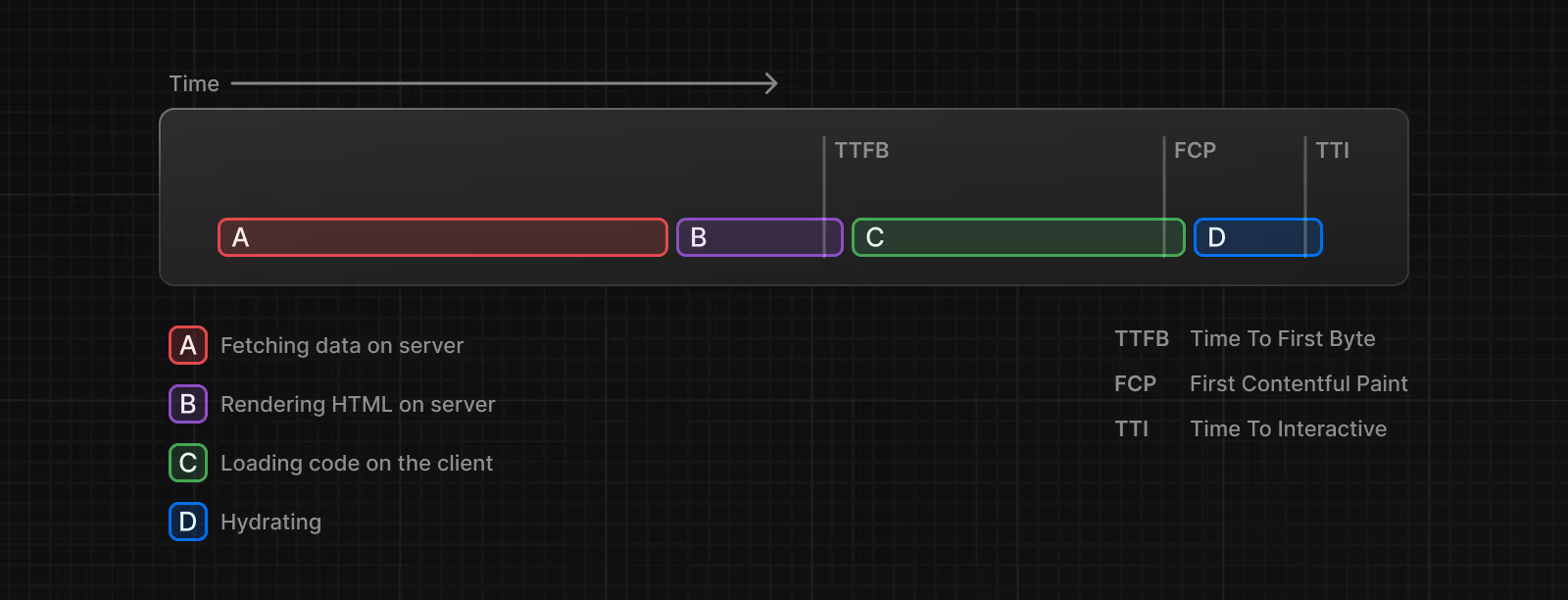 waterfall 방식의 SSR (Next.js Docs)
waterfall 방식의 SSR (Next.js Docs)
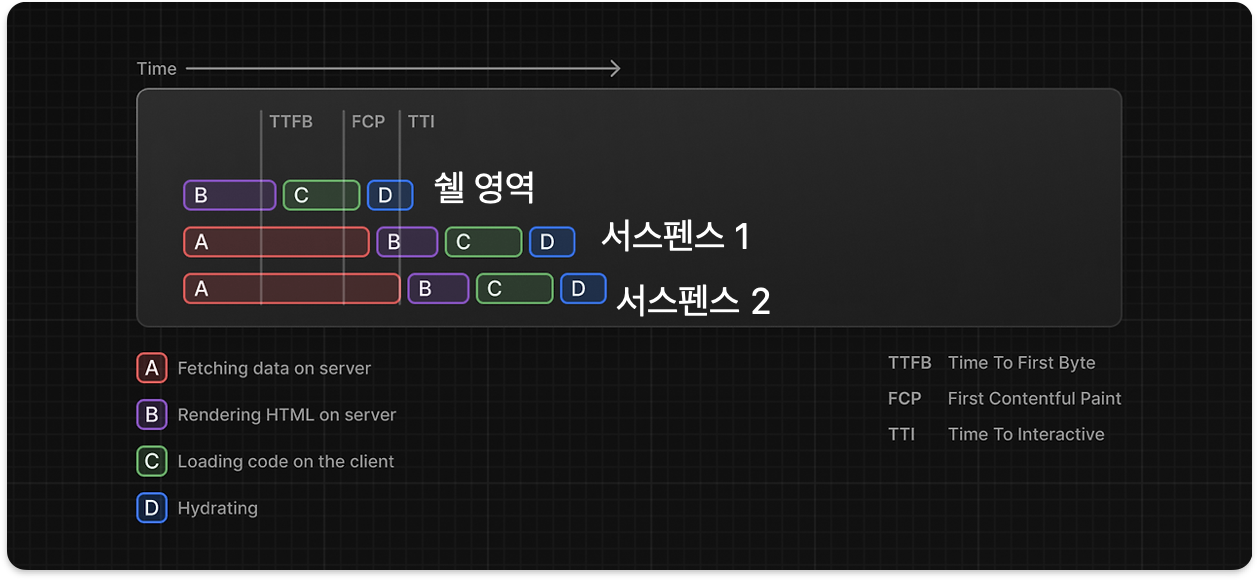
 출처 : New Suspense SSR Architecture in React 18 #37
출처 : New Suspense SSR Architecture in React 18 #37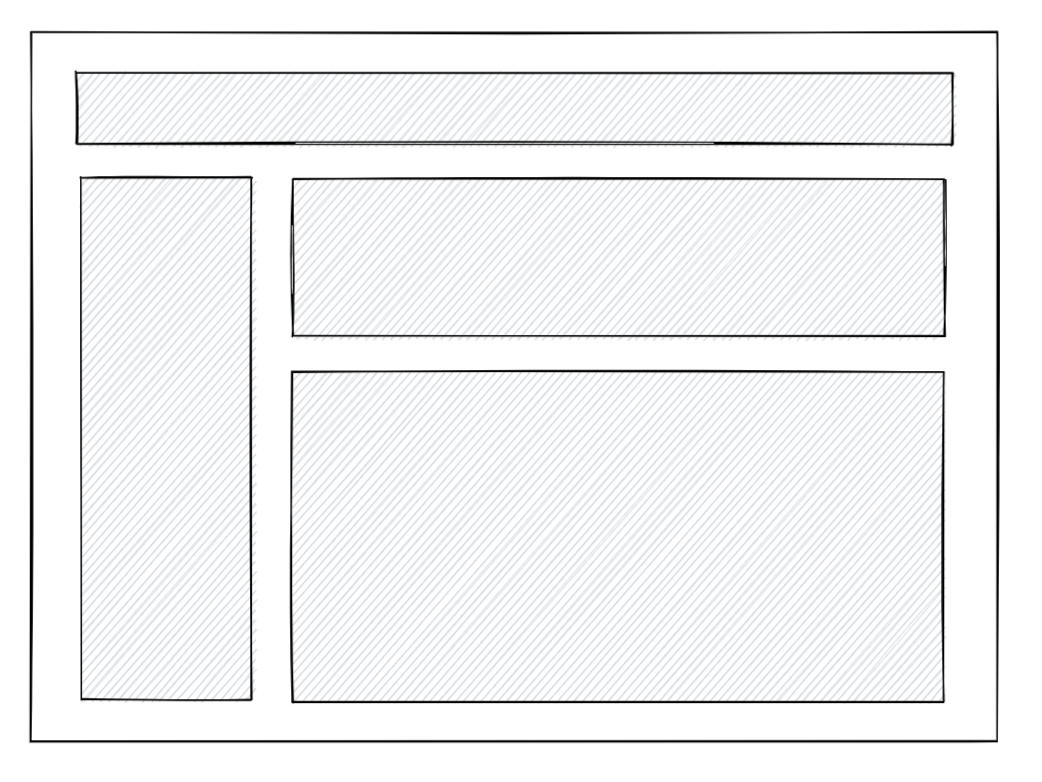 출처 : New Suspense SSR Architecture in React 18 #37
출처 : New Suspense SSR Architecture in React 18 #37