[React] 다양한 의미로 쓰이는 렌더링 이해하기
1. 개요
렌더링은 웹 관련 개념에 자주 등장하는 용어입니다. 기본적으로 "렌더링"은 무언가를 그리거나, 현재 상태에서 다른 상태로 변화시키는 과정을 의미하기 때문에 다양한 웹 개념에서 사용되고 있습니다.
예를 들어봅시다.
서버 사이드 렌더링은 서버에서 리액트를 렌더링하여 초기 HTML을 생성합니다. 브라우저는 서버로부터 받은 HTML을 활용해 브라우저 렌더링을 수행합니다.
이 문장에서 "렌더링"이라는 단어는 세 번 사용되었지만, 이들은 서로 다른 개념을 내포하고 있습니다. 웹 개발 경험이 많은 개발자는 개별 용어들이 의미하는 바를 알고 있기에 문장의 의미를 쉽게 파악할 수 있겠지만, 웹의 발전 과정을 잘 알지 못하는 개발자에게는 문장의 의미가 모호하게 느껴질 수 있습니다. 마치 문장을 이해한 것 같지만, 실제로는 말의 의미를 파악하지 못한 경우가 많다고 생각합니다. 이 글을 쓰고 있는 저 또한 후자에 해당하는 개발자로서 도대체 렌더링이 뭐길래 사람을 혼란스럽게 만드는지 참 답답했었습니다.
어쨋든 컴퓨터 분야를 공부하다보면 하나의 단어가 여러 종류의 개념에 사용되거나 하나의 대상을 여러가지 다른 단어로 부르는 일이 비일비재합니다. 그러니 "렌더링"이라는 용어가 상황에 따라 다른 의미를 갖는다는 점을 인식하고, 각각의 개념을 구분해서 이해하는 것이 중요합니다. 이 글에서 설명할 서버 사이드 렌더링, 리액트 렌더링, 브라우저 렌더링의 차이를 구분할 수 있다면 리액트의 동작 원리를 훨씬 쉽게 파악할 수 있다고 생각합니다.
이 글은 리액트 18 이후 등장한 서버 컴포넌트를 고려하지 않습니다. 서버 컴포넌트까지 포함하여 렌더링을 설명하면, 이미 혼란스러운 개념이 더욱 혼란스러워질 수 있기 때문입니다. 서버 컴포넌트와 관련된 내용은 1부 리액트 18이 해결하려는 문제들에서 다루고 있으니 이를 참고하시기 바랍니다.
2. CSR과 SSR
요즘 웹 기술의 추세는 서버 사이드 렌더링(SSR) 입니다. 16년에 리액트로 SSR을 지원하는 next.js가 출시되었고, 22년 업데이트 된 리액트 18에서는 스트리밍, 선택적 hydration, 서버 컴포넌트 등 서버 기능이 대폭 강화 되었습니다.
개발자 입장에서는 SSR과 CSR을 상황에 맞게 선택할 수 있는 유연성이 생겼다는 점에서 긍정적입니다. 하지만 선택지가 많아진 만큼, 올바른 결정을 내리기 위해서는 SSR과 CSR의 차이를 명확히 이해하는 것이 중요합니다.
단순히 CSR과 SSR의 개념적 차이를 아는 것보다, 리액트 렌더링과 브라우저 렌더링의 관점에서 어떻게 다른지 이해하는 것이 더욱 중요합니다. 이는 SSR과 CSR 구현 방식에서 리액트의 렌더링 과정과 내부 처리 방식이 다르게 동작하기 때문입니다. 이에 대한 차이는 글 전반에 걸쳐서 소개할 예정이므로 먼저 CSR과 SSR의 기본 개념을 살펴보겠습니다.
2.1. 클라이언트 사이드 렌더링(CSR)
CSR과 SSR에서의 렌더링(rendering)은 초기 컨텐츠가 생성 되는 위치 또는 시점을 의미합니다.
CSR은 클라이언트(=브라우저)가 컨텐츠를 직접 생성하는 반면, SSR은 서버가 사용자가 요청한 컨텐츠를 직접 생성하여 클라이언트에 제공합니다.
리액트 18에 서버 컴포넌트가 등장하면서 이러한 개념의 구분에 모호함이 있지만, 여기서는 일반적인 의미의 CSR과 SSR를 설명하겠습니다. 서버 컴포넌트를 사용하는 환경이라면 서버와 클라이언트가 함께 컨텐츠를 생성합니다. 자세한 설명은 1부 리액트 18이 해결하려는 문제들을 참고 바랍니다.
CSR의 전반적인 렌더링 흐름을 이해해 보겠습니다.
-
CSR로 구현된 페이지에 접속합니다.(ex www.example.com)
-
서버는 클라이언트에 이미 존재하는 HTML 파일을 전송합니다. HTML 내부에는 기본 태그와 리액트 코드를 실행하는
script태그만이 존재합니다. -
브라우저는 서버로부터 첫 HTML 패킷을 받으면 HTML 파싱을 시작하고, main.js가 포함된 스크립트 태그를 만나면 코드를 다운로드 받습니다. 이 과정에서 사용자는 비어있는 흰 화면을 처음 마주하게 됩니다. HTML에는 아무런 컨텐츠가 없기 때문입니다.
-
스크립트가 다운로드되면 DOM Tree 생성이 완료되기까지 JS 실행을 대기합니다. 대기하는 이유는 main.js의 스크립트 타입이 module이라 defer 방식으로 다뤄지기 때문입니다.
-
HTML 파싱이 완료되면 브라우저는 main.js를 실행해 리액트 초기 렌더(initial render)를 수행합니다. (리액트 초기 렌더가 무엇인지는 다음 장에서 설명합니다.)
-
리액트 렌더를 수행하면 리액트는 그 결과로 UI 데이터(또는 Virtual DOM이라고 부릅니다.)를 생성합니다. 리액트는 이렇게 만든 UI 데이터를 기반으로 브라우저 DOM API를 이용해 DOM Element를 생성하고, 생성한 Element를 브라우저 DOM에 삽입합니다.
-
브라우저 DOM에 Element가 삽입되면 브라우저는 브라우저 렌더링을 재수행하여 비어있는 사용자 화면에 컨텐츠를 그려냅니다. (브라우저 렌더링은 다음 장에서 설명하겠습니다.)
-
화면에 컨텐츠가 그려지고 사용자는 페이지와 상호작용 할 수 있습니다.
2.2. 서버 사이드 렌더링(SSR)
SSR은 클라이언트에서 요청한 컨텐츠가 포함된 HTML 파일을 서버에서 생성하여 클라이언트로 전송합니다. 서버에서 이미 완성된 페이지를 제공하므로 사용자 입장에서는 컨텐츠를 매우 빠르게 볼 수 있습니다.
-
클라이언트가 SSR로 구현된 페이지에 접속합니다. (ex www.example.com)
-
서버는 컨텐츠에 필요한 데이터를 수집한 뒤 서버 단에서 리액트 렌더를 수행하며, 그 결과로 사용자가 요청한 컨텐츠가 포함된 HTML 파일이 생성됩니다.
-
서버는 HTML 파일을 브라우저로 보내고, 브라우저는 서버로부터 첫 HTML 패킷을 받으면서 HTML 파싱을 시작합니다.
-
서버에서 제공한 HTML 내부에는 클라이언트에서 리액트를 실행하는 스크립트가 존재합니다. HTML 컨텐츠를 리액트에서 관리하기 위한 절차로 이해하면 되겠습니다. 브라우저가 HTML을 파싱하는 중에 해당 Script를 만나면 다운로드를 요청합니다.
-
초기 브라우저 렌더링이 완료되어 서버에서 생성한 컨텐츠가 사용자에게 보여지고 있습니다. 하지만 아직 브라우저에서의 리액트 관련 처리가 완료되지 않아 브라우저와 상호작용이 불가합니다. 상호작용을 위해선 서버에서 생성한 컨텐츠를 리액트가 관리하도록 동기화 해야합니다. 이러한 과정을 Hydration이라 합니다. 이 작업은 브라우저 DOM 트리와 리액트 UI 데이터(=Virtual DOM)가 일치한지를 확인 후 이벤트 리스너를 붙이는 절차를 수행합니다.
-
클라이언트에서 Hydration이 완료되면 사용자는 페이지와 상호작용 할 수 있습니다.
SSR에서 기억할 점은 리액트가 서버에서 한 번, 클라이언트에서 한 번, 총 두 번 실행 된다는 점입니다.
3. 리액트 렌더링 사이클
앞서 설명한 CSR과 SSR에 대한 기본 동작 방식을 바탕으로 리액트 렌더링이 의미하는 바가 무엇인지 소개하겠습니다.
3.1. CSR에서의 리액트 렌더링 사이클
리액트가 페이지를 생성하고 제거하는 절차를 리액트 사이클 또는 리액트 수명주기라고 합니다. 리뉴얼 된 리액트 공식문서는 리액트의 사이클을 Trigger → Render → Commit 세 단계로 구분하여 설명하고 있습니다.
일반적으로 리액트 렌더링이라는 단어에는 두 가지 의미를 갖고 있습니다. 가장 보편적으로는 리액트 렌더링은 두번째 단계인 Render 단계를 의미합니다. 하지만 일부 글에서는 더 상위 개념인 리액트 사이클(Trigger-Render-Commit)을 의미할 때도 있습니다.
이 글에서는 리액트 Render 단계를 리액트 렌더로 표현하고 리액트 사이클(Trigger-Render-Commit)을 렌더링 사이클이라 표현하도록 하겠습니다.
Trigger-Render-Commit
Trigger 단계는 페이지의 변화를 리액트에게 알리는 단계입니다. 브라우저에 대한 변화가 필요함을 감지하면, 리액트는 이를 화면에 반영하기 위해 Render 단계로 넘어갑니다.
Render 단계는 리액트의 핵심으로서, 리액트 관련 글에서 때 자주 나오는 리액트 렌더링을 수행한다.고 할 때를 의미합니다. 이 Render 단계가 끝나면 UI 데이터라 불리우는 JS 객체를 생성합니다. UI 데이터를 흔히들 Virtual DOM 이라고도 부르기도 합니다.
끝으로 Commit 단계는 Render 단계에서의 결과물인 UI 데이터를 활용해 브라우저에게 업데이트 된 화면을 그려달라고 요청하는 단계입니다. 리액트는 페이지 내 변경될 사항이 어디인지를 요청하면 브라우저 내 여러 모듈은 이러한 요청을 처리하여 화면을 그립니다.
3.1.1. Trigger
트리거(Trigger)는 특정 행동을 유발하는 요소를 의미합니다. 총기의 방아쇠(trigger)를 당기면 총알이 발사되듯이, React에서의 트리거는 특정 조건이 충족될 때 리액트 Render 단계를 실행하도록 요청하는 역할을 합니다.
- 페이지가 최초로 로드될 때
- 컴포넌트의 props 변화 또는 리액트에서 관리하는 상태(State) 변화
페이지가 처음 로드되면 브라우저는 서버에서 제공된 HTML을 파싱하기 시작하는데, 이 HTML 안에는 React를 실행하는 <script> 태그가 포함되어 있습니다. 브라우저는 HTML을 파싱하는 도중 <script> 태그를 만나면 해당 코드를 다운로드합니다.
브라우저가 다운받은 script 코드는 일반적으로 아래와 같습니다. 브라우저의 js 엔진이 해당 코드를 처리하는 과정은 리액트가 트리거되는 과정입니다. createRoot와 render를 통해 실제 Render 단계로 넘어가게 됩니다.
// main.js
import { createRoot } from "react-dom/client";
import App from "app";
const domNode = document.getElementById("root"); // 브라우저 DOM 노드
const root = createRoot(domNode);
root.render(<App />); // App은 리액트 노드
// render 실행 시 domNode 내부의 DOM Element 전부 제거리액트는 모든 변화를 감지하지 않는다
앞의 과정은 페이지가 최초로 로드되는 과정에서 Trigger 단계를 설명했습니다. 이번에는 트리거의 두 번째 조건인 컴포넌트의 props 변화 또는 리액트에서 관리하는 상태(State) 변화에 대해 알아보겠습니다.
페이지가 로드된 후, 사용자는 페이지와 상호작용이 가능합니다. 버튼을 클릭하거나, Input에 값을 입력하거나 하는 등의 브라우저와 상호작용하는 과정에서 페이지의 상태는 계속해서 변화합니다.
리액트는 이러한 변화사항을 효율적으로 관리하기 위해 사용되는 도구입니다. 그렇다고 페이지 내 발생하는 모든 변화를 리액트가 감지하고 관여하고 처리하는 것은 아닙니다. 사실 리액트는 수동적인 존재로서, 페이지의 변화를 리액트에게 알려야만 작업을 처리할 수 있습니다.
리액트는 아래 세 종류의 함수를 통해서만 변화가 발생했음을 감지할 수 있습니다. 해당 함수는 리액트의 상태를 관리하고(=데이터를 저장하고) Render를 수행하는 코드가 포함되어 있습니다. 리액트에서 관리 중인 데이터가 변경되면 그에 맞게 페이지도 업데이트 되도록 하는 원리입니다.
- useState
- createContext에서 관리하는 값의 변화
- useReducer
이처럼 리액트는 페이지의 모든 변화를 감지하는 것이 아닌, 특정 함수 호출을 통해서만 상태 변화를 감지하고 렌더링을 수행함을 이해하는 것이 중요합니다.
위의 함수들과 다르게 데이터를 관리하지만, 리액트에게 렌더링을 요청하지 않는 함수가 있습니다. 바로
useRef입니다.useRef는 1. 데이터가 변화해도 리액트 렌더가 필요하지 않은 경우와 2. 특정 DOM 엘리먼트에 직접 접근이 필요한 경우 사용합니다.
3.1.2. Render
Trigger 단계 다음인 Render 단계는 현재 페이지의 변화사항을 분석하고, 최적의 브라우저 렌더링 방법을 계산하는 과정입니다.
계산의 결과이자 Render 단계의 결과물은 UI 데이터(=Virtual DOM)라 하며, 리액트가 브라우저를 어떻게 최적으로 렌더링 할지에 대한 청사진과 같은 역할을 합니다. Render의 결과물인 UI 데이터는 앞으로 그려질 UI에 대한 청사진을 담고 있습니다. 이러한 JS 데이터를 만들기 위한 계산은 JS 내에서 전부 처리됩니다.
Render 단계의 핵심은 모든 과정이 JS엔진 내부에서 수행된다는 점입니다. 브라우저를 직접적으로 건드리지 않습니다.
최초 로딩 시 Render 처리
최초 로딩 시 실행했던 main.js를 다시 보겠습니다.
// main.js
import { createRoot } from "react-dom/client";
import App from "app";
const domNode = document.getElementById("root"); // 브라우저 DOM 노드
const root = createRoot(domNode);
root.render(<App />); // App은 리액트 노드
// render 실행 시 domNode 내부의 DOM Element 전부 제거CSR에서는 createRoot(domNode, options)을 사용해 초기 렌더(initial Render)를 수행합니다. domNode에는 실제 브라우저 DOM 노드가 들어갑니다. 리액트는 인자로 들어간 DOM 노드 내부에 렌더링 결과를 업데이트 합니다.
브라우저는 createRoot으로 생성한 root 객체의 render매서드를 실행해 Render 단계를 트리거 합니다. 이때 Render 단계는 리액트를 처음 실행시키는 것이므로 루트 리액트 노드부터 시작하는 전체 리액트 노드에 대한 UI 데이터를 생성합니다.
상태 업데이트 시 Render 처리
페이지가 로딩 된 이후 사용자가 브라우저와 상호작용하는 과정에서 useState, useReducer 등 리액트의 setter 함수가 호출되면 상태 변화에 따른 Render를 트리거 합니다.
리액트는 초기 페이지 로딩 이후, 현재 페이지의 UI 데이터를 currentTree라는 변수명으로 관리하고 있는데요, setter 함수에 의해 리액트가 상태를 감지하면, 리액트는 업데이트가 필요한 컴포넌트부터 시작하는 UI 데이터를 workingInProgress를 생성합니다.
초기 로딩 시 Render 단계는 루트 리액트 노드에서부터 시작하는 UI 데이터를 계산했다면, 상태 업데이트 발생 시 Render 단계는 업데이트가 필요한 컴포넌트부터 UI 데이터를 생성합니다. 리액트는 currentTree와 새로 업데이트 된 UI 데이터인 workingInProgress를 비교해 실제로 어떠한 컴포넌트를 변경해야할지를 기록합니다. 이에 대한 과정은 Fiber 엔진이 담당하고 있습니다.
Fiber 엔진에서 workingInProgress를 생성하고 이를 비교해 DOM 업데이트가 필요한 부분을 찾는 절차는 아래와 같이 도식화한 글을 참고 바랍니다.
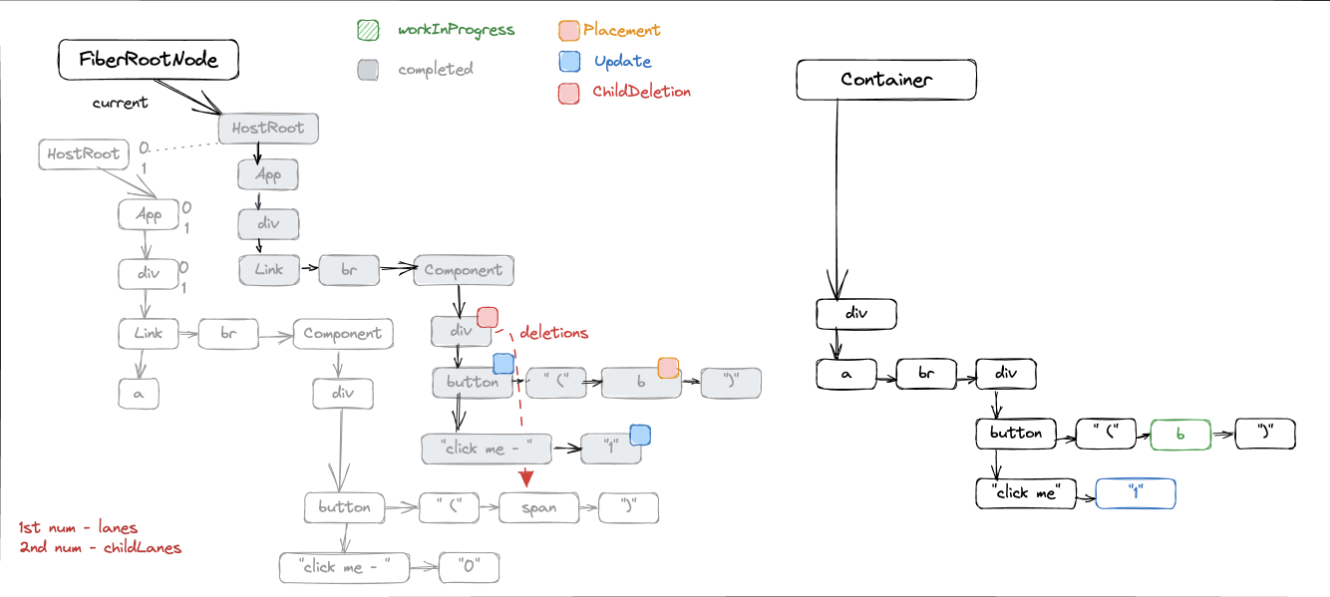
Fiber에 대한 상세 작동원리는 다음의 링크로 대체하겠습니다. 양질의 글이므로 Fiber에 대한 이해가 필요하시다면 읽어보기를 추천합니다.
-
Decoding React’s Reconciliation and Diffing Algorithm: A Brief Overview
-
React Fiber: Reconciliation under the hood (with links to source code)
리액트가 효율적인 이유
리액트가 인기를 얻고 지금까지 사용되는 이유는 UI 데이터 기반의 브라우저 렌더링 덕분입니다. 리액트는 페이지 변경 사항을 JS 객체인 UI 데이터에 업데이트한 뒤 이를 기반으로 한 번의 브라우저 렌더링만을 수행하므로 매우 효율적입니다.
리액트가 청사진 없이 DOM 조작 코드를 만날때마다 DOM을 업데이트한다고 생각해보세요. DOM이 업데이트 될때마다 매번 브라우저 렌더링을 수행해야하는데, 일련의 복잡한 처리 과정을 수행하는 브라우저 렌더링에는 많은 컴퓨팅 리소스를 필요로 합니다. 반면 리액트는 DOM 업데이트가 필요할 때마다 실제 브라우저를 업데이트 하는 대신 JS 객체를 업데이트 합니다. JS 객체의 값을 변경하는 것은 브라우저 렌더링을 유발하는 DOM 업데이트에 비해서는 훨씬 간단한 작업입니다.
특히 SPA(Single Page Application) 환경에서는 이러한 방식이 더욱 유용합니다. 복잡한 SPA에서는 DOM 조작이 빈번하게 발생하기 때문입니다. 예를 들어, 페이지 이동(라우팅)만 하더라도 새로운 UI를 렌더링해야 합니다.
이때 UI 데이터를 사용하지 않고 즉각 즉각 DOM을 변경한다면 매번 브라우저 렌더링이 수행되어 성능 저하로 이어질 것입니다. 하지만 리액트는 UI가 그려질 청사진을 먼저 계산한 후, 최적화된 방식으로 한 번에 렌더링을 수행하기 때문에 SPA에서도 부드럽고 빠른 UI 업데이트가 가능합니다.
더 깊은 이해를 원하신다면 [번역] 리액트에 대해서 그 누구도 제대로 설명하기 어려운 것. 왜 Virtual DOM 인가? | VELOPERT.LOG를 참고해 보세요.
3.1.3. Commit
Commit은 Render 단계 결과물인 UI 데이터를 활용해 실제 브라우저의 DOM을 조작하는 단계입니다.
Render 단계에서 설명했듯 코드를 읽어내려가면서 하나하나 DOM 조작을 처리하여 매번 브라우저 렌더링을 유발하는 작업은 매우 비효율적입니다. 리액트는 이러한 비효율적인 부분을 개선하기 위해 고안되었으며 DOM 조작을 한 번만 수행할 수 있도록 리액트 내부에서 업데이트를 관리하고 최적화합니다. 리액트는 Render 단계에서 최적의 업데이트 방법을 계산한 뒤, 훌륭한 결과물을 활용해 브라우저를 업데이트합니다.
초기 로딩 시
초기 로딩 시의 Render 단계는 모든 리액트 노드에 대한 UI 데이터를 생성합니다. Render 단계에서 생성한 UI 데이터는 실제 브라우저 DOM을 생성하기 위해 사용합니다.
리액트는 UI 데이터와 web API를 활용해 브라우저에게 컨텐츠가 포함된 DOM을 생성하도록 요청합니다. DOM이 생성되면 리액트는 완성된 DOM 노드를 id=root인 div 엘리먼트의 children에 위치시키도록 요청합니다. 브라우저 엔진은 브라우저 DOM의 변화가 발생하였으므로, 브라우저 렌더링을 수행하여 업데이트 된 페이지를 실제로 그려냅니다.
리액트가 브라우저 DOM을 생성하고 children에 삽입하도록 요청하는 절차는 아래와 같이 도식화한 글을 참고하시면 보다 직관적인 이해가 가능합니다.
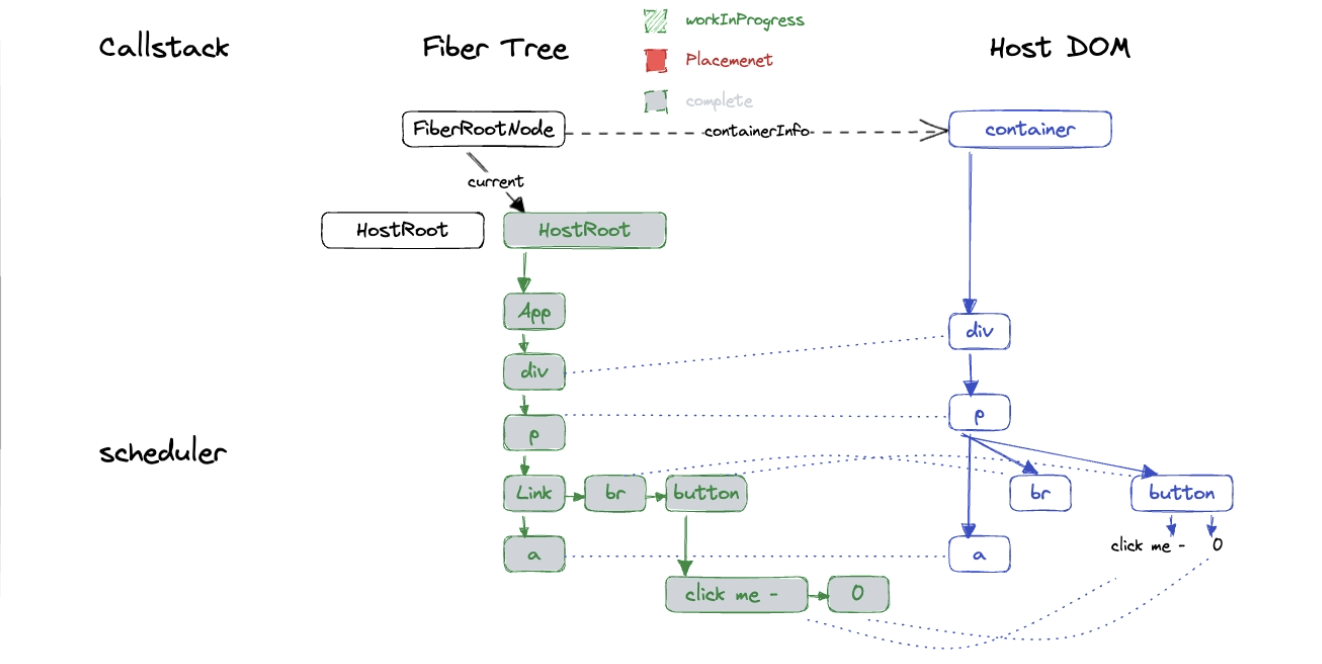
상태 업데이트 시
상태 업데이트는 리액트 루트 전체를 다시 그리지 않고 변경이 필요한 노드와 그 하위 노드를 렌더한다고 했습니다. 그리고 렌더 단계는 변경이 필요한 영역에 대해서 어느 부분을 실제 변경해야 할지를 체크하여 UI 데이터를 생성합니다. 이 UI 데이터는 리액트 노드의 일부 영역만 포함할 뿐아니라 해당 영역 안에서 실제 변경되어야 할 영역이 어디인지를 다루는 청사진입니다. 커밋 단계에서는 이러한 청사진을 활용해 변경이 필요한 부분만 핀 포인트로 업데이트 합니다.
3.2. SSR에서의 리액트 렌더링 사이클
다음으로 SSR에서의 리액트 사이클을 설명하겠습니다. CSR에서의 리액트 렌더링 사이클과 다른 점은 페이지 최초 로딩 시 서버가 개입한다는 것입니다. 상태 업데이트에 의한 페이지 변화는 CSR과 동일하게 클라이언트 자체적으로 업데이트합니다.
SSR에서의 렌더링 사이클은 다음의 순서를 가집니다.
-
사용자가 서버에 페이지를 요청합니다.
-
서버는 컨텐츠 생성에 필요한 데이터를 수집하고 리액트를 트리거합니다.
-
컨텐츠에 대한 HTML 파일을 생성한 뒤 브라우저에 제공합니다.
-
클라이언트에서 Hydration을 수행합니다. Hydration은 HTML을 활용해 만든 브라우저 DOM Tree를 리액트가 관리하도록 동기화하는 절차입니다.
-
초기 로딩이 완료됩니다.
-
상태 업데이트 발생 시 사이클은 CSR과 동일합니다.
서버의 역할은 어디까지인가?
초기 렌더 이후 발생하는 상태(State) 업데이트는 클라이언트의 리액트에서 관리합니다. 페이지 이동, QueryParameter 변경 등 라우팅의 변화가 발생한 경우는 서버 컴포넌트 사용 여부에 따라 차이가 있습니다. 여기서는 Pages Router와 같이 클라이언트 컴포넌트만을 사용한 경우에만 설명하도록 하겠습니다.
QueryParameter 변경 등 라우팅의 변화가 발생한 경우는 초기 렌더와 동일한 방식으로 처리됩니다. 예로들어 제품 검색 시 필터 옵션 변경을 QueryParameter로 관리하게 되면 서버로부터 매번 새로운 HTML을 받아 렌더를 시작합니다.
SWR 라이브러리 공식문서는 Pages Router로 구현 됐는데요. 공식문서의 URL을 https://swr.vercel.app/docs/mutation?key=test와 같이 parameter를 변경해서 요청하면 서버로부터 이에 대한 URL에 대한 HTML을 새롭게 전송받습니다.

3.2.1. Trigger
서버에서의 리액트가 트리거 되는 시점은 사용자가 서버에 페이지를 요청할 때 입니다.
서버는 컨텐츠 생성에 필요한 데이터를 수집한 뒤 renderToPipableStream(reactNode, options)라는 서버에서 실행가능한 리액트 함수 실행시켜 서버단에서의 Render를 시작합니다.
renderToPipeableStream(reactNode, options)의 인자인 reactNode는 서버에서 렌더링하려는 리액트 노드입니다. options는 bootstrapScript외 다양한 옵션이 존재하지만, 이 글에서는 bootstrapScript 만을 다루도록 하겠습니다. 그 외 다른 옵션은 공식문서에 설명하고 있으니 공식문서를 참고 바랍니다.
// server.tsx
import express from "express";
import React from "react";
import ReactDOMServer from "react-dom/server";
import { App } from "./app.tsx";
const port = Number.parseInt(process.env.PORT || "3000", 10);
const app = express();
app.get("/", (_, res) => {
const { pipe } = renderToPipeableStream(<App />, {
bootstrapScripts: ["/main.js"],
});
});
// app.tsx
export default function App() {
return (
<html>
<head>
<meta charSet="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="stylesheet" href="/styles.css"></link>
<title>My app</title>
</head>
<body>
<div>Contents...</div>
<Suspense fallback={<div>Loading....</div>}>
<Router />
</Suspense>
<div>Contents...</div>
</body>
</html>
);
}bootstrapScripts는 클라이언트에서 리액트를 실행시키기 위한 경로를 설정하는 옵션입니다. bootstrapScripts에 클라이언트 단에서의 리액트를 실행하는 파일명을 입력하면, 아래와 같이 클라이언트로 보낼 HTML 하단에 <script src="/main.js" async=""></script>가 삽입됩니다.
<!DOCTYPE html>
<html>
<!-- ... 컴포넌트의 HTML ... -->
</html>
<script src="/main.js" async=""></script>3.2.2. Render와 Hydration
SSR에서의 리액트 Render는 서버와 클라이언트 두 곳에서 발생합니다. 서버에서 일어나는 과정을 Render라하고 이후 클라이언트에서 발생하는 과정을 Hydrationd이라 합니다.
서버에서 renderToPipeableStream(reactNode, options)의 옵션 중 하나로 bootstrapScripts에 대해 설명했는데요.
bootstrap으로 설정한 main.js 안에는 클라이언트에서 Hydration을 트리거하는 코드가 포함되어 있습니다. hydrateRoot(domNode, reactNode, options)가 바로 클라이언트에서의 트리거 함수입니다.
브라우저 JS 엔진은 main.js의 hydrateRoot(domNode, reactNode);을 실행하면 클라이언트 리액트는 Hydration을 수행해 서버로부터 받은 컨텐츠를 클라이언트 리액트에서 관리하도록 합니다.
import { hydrateRoot } from "react-dom/client";
const domNode = document.getElementById("root"); // 실제 dom Node
hydrateRoot(domNode, reactNode);클라이언트에서 Hydration을 시작하기 위해서는 두 가지 조건이 선행되어야 합니다.
-
브라우저가 DOM Tree를 완성한다.
-
리액트 루트 노드에서부터 시작한 전체 UI 데이터가 존재한다.
두 조건이 필요한 이유는 브라우저 DOM Tree와 UI 데이터를 가지고 재조정(Reconciliation)을 거치기 때문입니다. 이 과정에서 브라우저 DOM Tree와 UI 데이터가 일치하지 않는다면 Hydration 에러가 발생하고 createRoot을 처음부터 실행합니다.
리액트는 브라우저 DOM Tree와 UI 데이터가 동일하다고 판단되면 브라우저 DOM Tree를 리액트가 관리할 수 있도록 하는 Hydration을 수행합니다. 이 과정을 통해 리액트 컴포넌트의 로직들이 브라우저 DOM Element에 반영되어 최종적으로 리액트에서 관리하는 페이지를 완성합니다.
4. 브라우저 렌더링
브라우저 렌더링은 서버에서 받아온 HTML, CSS, JavaScript 등을 해석하고 화면에 표시하는 전체 과정을 의미합니다. 이 과정은 여러 모듈이 협력하여 수행되며, CPU뿐만 아니라 GPU까지 활용하는 등 상당한 리소스를 필요로 합니다.
브라우저는 여러 개의 핵심 모듈로 구성되어 있으며, 각각의 역할이 분명하게 구분됩니다. 예를 들어, 크롬(Chrome) 브라우저를 기준으로 보면 다음과 같은 주요 모듈이 있습니다.
-
V8: 자바스크립트(JS)를 해석하고 실행하는 엔진
-
Blink: HTML을 파싱하여 DOM(Document Object Model) 트리를 생성하는 엔진
-
CSS 파서: CSS를 해석하여 CSSOM(CSS Object Model) 트리를 생성
-
UI 백엔드: 실제 화면에 콘텐츠를 렌더링
브라우저가 화면을 그리는 과정은 아래의 순서로 이루어지며, 리액트 렌더링도 이 흐름의 일부로 동작합니다.
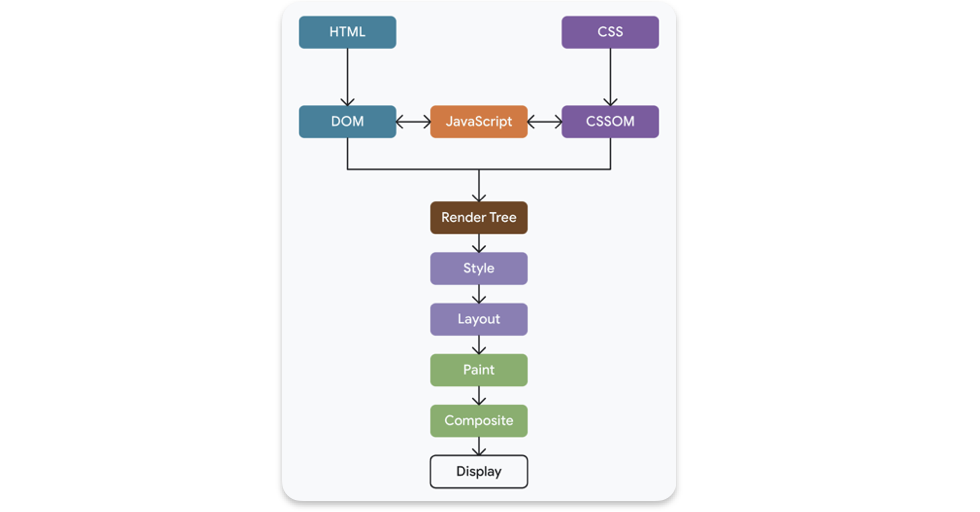
리액트는 JS 엔진(V8)에서 실행됩니다. 이미지의 주황색 영역은 리액트가 실제 실행되는 영역입니다. 리액트 사이클 마지막 단계인 Commit에서는 Render 결과로 얻은 UI 데이터로 브라우저에 작업을 요청합니다. 이러한 작업은 이미지에서 JS와 DOM의 상호작용으로(<->)로 그려지고 있습니다.
이 장에서는 브라우저 렌더링의 전체적인 과정보다는 리액트 기반 페이지가 브라우저에서 어떻게 렌더링되는지에 초점을 맞춰 설명하겠습니다.
브라우저 렌더링 절차에 대한 더 깊은 이해가 필요하신 분들은 아래 공유한 링크를 참고해 주세요.
- [mdn] 웹페이지를 표시한다는 것: 브라우저는 어떻게 동작하는가
- [mdn] 중요 렌더링 경로
- [web.dev] Don't fight the browser preload scanner
- [web.dev] Understand the critical path
- 💻 브라우저 렌더링 - CRP 멈춰!
4.1. HMTL 파싱과 TTFB
브라우저 렌더링은 서버로부터 HTML 파일을 요청하는 것에서 시작합니다. 이때 접속하고자 하는 페이지가 CSR로 구성된 경우라면 브라우저에 비어있는 HTML 파일을 제공합니다. 반면 SSR로 구성된 경우라면 컨텐츠가 포함된 HTML을 브라우저에게 제공합니다.
브라우저는 서버로부터 HTML에 대한 첫 패킷이 도착하면 HTML 파싱을 시작합니다. 일반적으로 웹 통신에서는 데이터를 14KB 단위로 전송하며, 브라우저는 전체 HTML을 다 받은 후 파싱을 시작하는 것이 아니라, 첫 번째 패킷이 도착하는 순간부터 HTML을 분석합니다.
브라우저는 HTML에 대한 패킷을 받자마자 파싱을 시작합니다!
이때 중요한 성능 지표가 Time to first byte(TTFB)입니다. TTFB는 서버에서 첫 번째 바이트를 응답하는 속도를 의미하며, 이 값이 빠를수록 브라우저는 더 빨리 페이지 파싱을 시작할 수 있습니다.
4.2. 리액트 렌더링 사이클과 FCP
HTML 패킷이 도착하면 브라우저 렌더링 엔진이 즉시 HTML을 파싱하기 시작합니다. 이 시점에서는 아직 화면에 콘텐츠가 표시되지 않아, 사용자는 흰 배경만 보게 됩니다.
SSR인지, CSR인지에 관계없이, HTML에는 클라이언트에서 리액트를 실행하는 <script> 태그가 포함되어 있습니다. 브라우저 렌더링 엔진은 HTML을 파싱하다가 <script> 태그를 만나면 리액트를 실행합니다.
CSR 방식의 리액트는 Render 단계를 거쳐 UI 데이터를 생성하고, 생성한 UI 데이터를 활용해 브라우저에 실제 DOM 엘리먼트 생성을 요청합니다. UI 데이터와 일치하는 DOM 노드가 생성되면 이를 브라우저 DOM에 반영할 수 있도록 브라우저에 요청합니다. 이러한 요청은 브라우저의 렌더링 엔진(예: 크롬의 Blink 엔진)이 담당합니다.
SSR 방식에서는 서버에서 이미 생성된 콘텐츠를 클라이언트에 제공하므로, 클라이언트가 직접 콘텐츠를 생성할 필요는 없습니다. 대신, Hydration 과정을 거쳐 서버에서 제공한 HTML을 리액트가 관리할 수 있도록 처리해야 합니다.
Hydration은 이미 완성된 브라우저 DOM 엘리먼트에 이벤트 리스너를 추가하는 과정입니다. 이 작업을 수행하려면 브라우저에서 DOM 트리 생성을 완료한 후 실행해야 합니다. 따라서, 클라이언트 측에서는 DOM 트리 생성이 끝난 다음 hydrateRoot를 실행해야 합니다.
가장 간단한 방법으로 HTML 내에서 <script> 태그를 최하단에 배치하는 방법이 있습니다. 실제로는 프레임워크들은 단순히 HTML의 <script> 위치를 조정하는 방식이 아니라, 번들러와의 조합을 통해 Hydration이 적절한 시점에 수행되도록 최적화합니다.
여기까지 진행되면 브라우저의 DOM 트리 생성이 완료되었습니다. 이제 CSSOM과 DOM 트리를 결합하여 Render Tree를 만들어 Layout을 계산하고, Paint 과정을 거쳐 콘텐츠를 화면에 표시합니다.
초기 렌더링 성능과 FCP
리액트의 초기 렌더링이 길어질수록, 사용자는 더 오랜 시간 동안 흰 화면을 보게 됩니다. 이를 평가하는 지표 중 하나가 **First Contentful Paint(FCP)**입니다. FCP란 사용자가 처음으로 콘텐츠를 보게 되는 순간까지의 시간을 측정하는 웹 성능 지표입니다.
리액트의 초기 Render 단계가 길어질수록 FCP가 지연되어, 사용자는 불편을 느끼고 SEO(검색 엔진 최적화)에도 부정적인 영향을 미칩니다.
따라서, FCP를 최소화하려면 초기 브라우저 렌더링을 최대한 빠르게 수행해야 합니다. 이를 위해, 최신 웹 기술에서는 DOM 트리 생성을 방해하는 요소를 줄이는 방식으로 최적화합니다.
특히, JS 파일 크기를 줄이거나 CSR에서 SSR로 전환하는 방법 등을 활용해, 초기 콘텐츠 표시 속도를 개선하는 방향으로 FCP를 최적화합니다.
4.3. State 업데이트에 의한 리렌더(re-render)
사용자의 행동의 결과 상태(state)가 업데이트 되면, 리액트는 render 단계를 수행해 업데이트가 필요한 UI 데이터를 생성하고, 직전의 UI 데이터와 비교해 DOM에 대한 부분 업데이트를 요청합니다.
브라우저는 리액트로부터 요청 받은 영역에 대한 DOM 업데이트를 처리합니다. 그리고 이는 브라우저 렌더링을 다시 수행하도록 트리거합니다.
물론 브라우저가 UI를 다시 그려야 할때, 모든 과정을 반복하지는 않습니다. 상태 변화가 발생하면 브라우저는 다음과 같은 최적화된 렌더링 절차를 따릅니다. 이떄는 DOM Tree, CSSOM Tree, Render Tree를 생성하는 단계를 건너뛰고 업데이트 종류에 따라 Layout 단계와 paint 단계부터 시작합니다.
margin, Padding, height, width와 같이 요소의 크기나 위치를 다시 계산해야 하는 경우라면 Layout 단계서부터 시작하며 이를 Reflow라 부릅니다. 반면 bg-color, box-shadow와 같은 기존의 layout을 다시금 사용하더라도 변화를 처리할 수 있다면 paint 단계서부터 시작하며 이를 Repaint라 합니다.
5. 마무리
컴퓨터 분야를 공부하면서 매번 느끼는 점은 하나의 용어를 다양한 상황, 다양한 개념을 설명하는데 사용한다는 것입니다. 제게는 웹 분야를 공부하면서 '렌더링' 이라는 단어가 그러했습니다. 렌더링은 어느 개념에서나 존재하고 다양한 단어와 조합되어 쓰이곤 하다보니 알다가도 뒤돌면 사람을 혼란스럽게 만듭니다.
아무래도 코드를 작성할 때 변수명을 작성하는게 어렵듯, 개념을 설명할 대상을 부르는 용어를 새로 만든는게 어렵지 않기 때문에 그런가 싶습니다. 렌더링 외에는 딱 맞는 용어가 없을수도 있구요.
아무튼, 이 글을 작성하고나니 이제는 렌더링에 대해 혼라스러워 할 일이 줄어든 것 같습니다. 그리고 렌더링의 의미 차이를 세세하게 파다보니 덕분에 브라우저 작동원리를 큰 그림으로 이해할 수 있기도 했구요.
얼마나 많은 분들이 이 글을 끝까지 읽으실지는 모르겠지만, 제 글이 렌더링이 갖고 있는 다양한 의미를 이해하는데 도움 되셨으면 좋겠습니다. 그리고 긴 글을 끝까지 읽어주셔서 감사합니다.